Prepare resources¶
You must prepare your environment for running a workflow, including NebulaGraph configurations, DAG configurations, NebulaGraph Analytics configurations and HDFS configurations.
Prerequisites¶
- NebulaGraph Analytics 3.5.0 or later have been deployed. For details, see NebulaGraph Analytics.
- Dag Controller have been deployed and started. For details, see Deploy Explorer.
Steps¶
-
At the top of the Explorer page, click Workflow.
-
Click Workflow Configuration in the upper right corner of the page.
-
Configure the following resources.
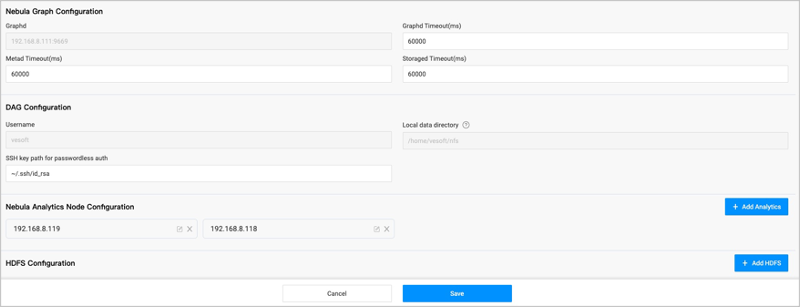
-
NebulaGraph configuration
The access address of the graph service that executes a graph query or to which the graph computing result is written. The default address is the address that you use to log into Explorer and can not be changed. You can set timeout periods for three services.
-
DAG configuration
The configuration of the Dag Controller for the graph computing.
- Username: The username to run the service, and does not need to be changed.
- Local data directory: The Analytics data directory, the shared directory of NFS service. By default, the workflow uses NFS to store the graph computing results, but the user needs to install NFS and mount the directory manually.
- SSH key path for passwordless auth: The path to the private key file of the machine where Dag Controller is located. It is used for SSH-free login between machines.
-
NebulaGraph Analytics configuration
Add the address of the NebulaGraph Analytics where the graph computing will be performed.
- Nebula Analytics Node IP address: fill in the new Analytics node IP address.
- Username: The username used for password-free access to this Analytics node. The username must be consistent across all Analytics nodes.
- SSH port number: Default is
22. - SSH key path for passwordless auth: Used for SSH-free login between machines. Default is
~/.ssh/id_rsa. - Local data directory: Default is
~/analytics-data. - ALGORITHM script path: Default is
~/nebula-analytics/scripts/run_algo.sh.
-
NFS configuration
Note
Users need to deploy the NFS Server on the Dag Controller machine and configure the shared directory by themselves, and then deploy the NFS client on all Analytics machines and mount the shared directory.
Enabled by default, the results of the task will be saved locally. Each Analytics node needs to be configured with a local data directory for NFS.
-
HDFS configuration (Optional)
By default, NFS is used to save the graph computing results. If you need to use HDFS, please install the HDFS client on the machine where Analytics is located first.
- HDFS name: Fill in the name of HDFS configuration, it is convenient to distinguish different HDFS configurations.
- HDFS path: The
fs.defaultFSconfiguration in HDFS. Support configure the save path, such ashdfs://192.168.8.100:9000/test. - HDFS username: The name of the user using HDFS.
-
-
Click Save.
-
Click Configuration Check in the upper right corner and click Start Check to check if the configuration is working.