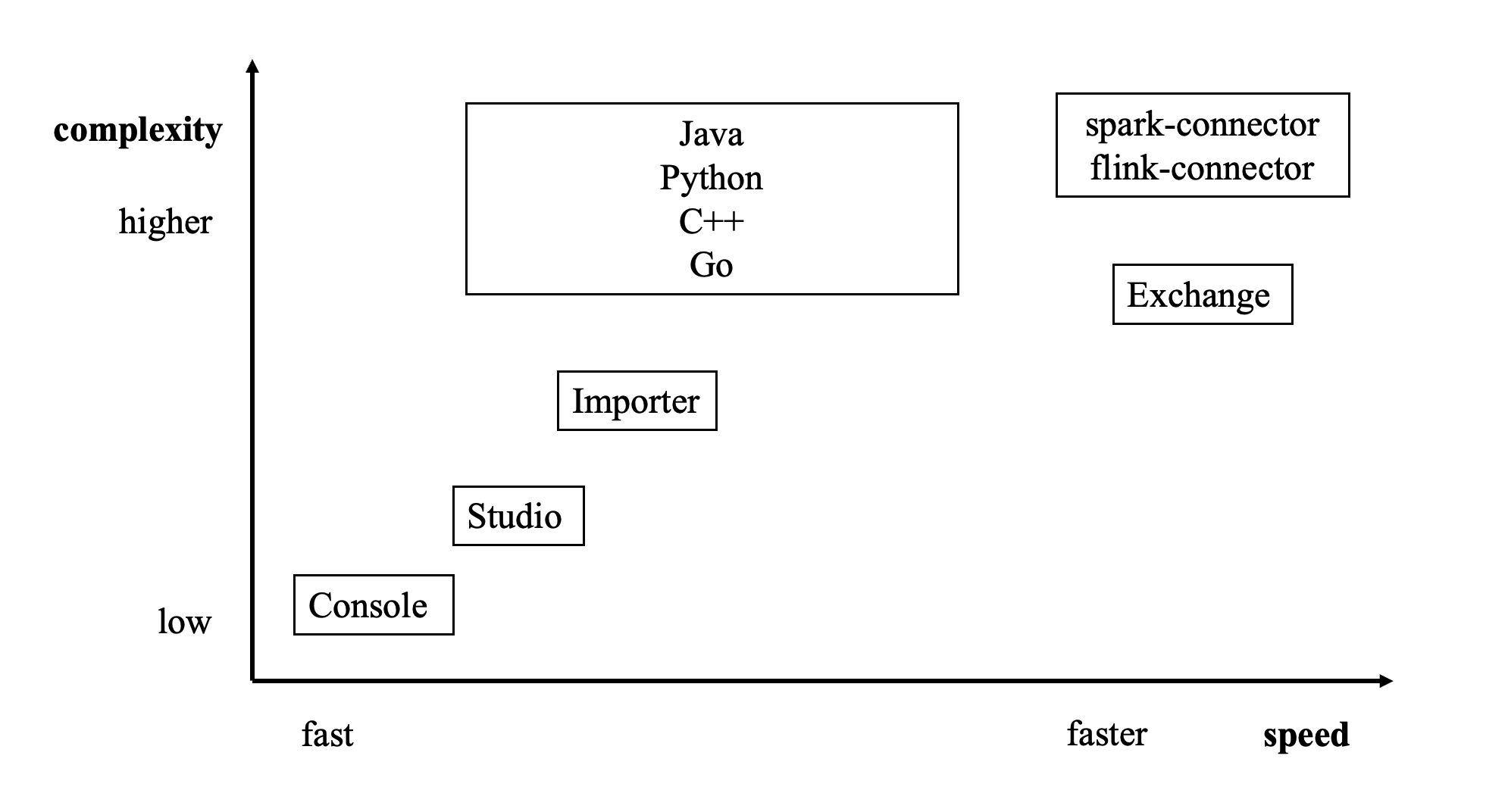
Import tools¶
There are many ways to write NebulaGraph 3.6.0:
- Import with the command -f: This method imports a small number of prepared nGQL files, which is suitable to prepare for a small amount of manual test data.
- Import with Studio: This method uses a browser to import multiple CSV files of this machine. A single file cannot exceed 100 MB, and its format is limited.
- Import with Importer: This method imports multiple CSV files on a single machine with unlimited size and flexible format. Suitable for scenarios with less than one billion records of data.
- Import with Exchange: This method imports from various distribution sources, such as Neo4j, Hive, MySQL, etc., which requires a Spark cluster. Suitable for scenarios with more than one billion records of data.
- Read and write APIs with Spark-connector/Flink-connector: This method requires you to write a small amount of code to make use of the APIs provided by Spark/Flink connector.
- Import with C++/GO/Java/Python SDK: This method imports in the way of writing programs, which requires certain programming and tuning skills.
The following figure shows the positions of these ways:
Export tools¶
- Read and write APIs with Spark-connector/Flink-connector: This method requires you to write a small amount of code to make use of the APIs provided by Spark/Flink connector.
-
Export the data in database to a CSV file or another graph space (different NebulaGraph database clusters are supported) using the export function of the Exchange.
Enterpriseonly
The export function is exclusively available in the Enterprise Edition. If you require access to this version, please contact us.
Last update:
February 18, 2024