Ecosystem tools overview¶
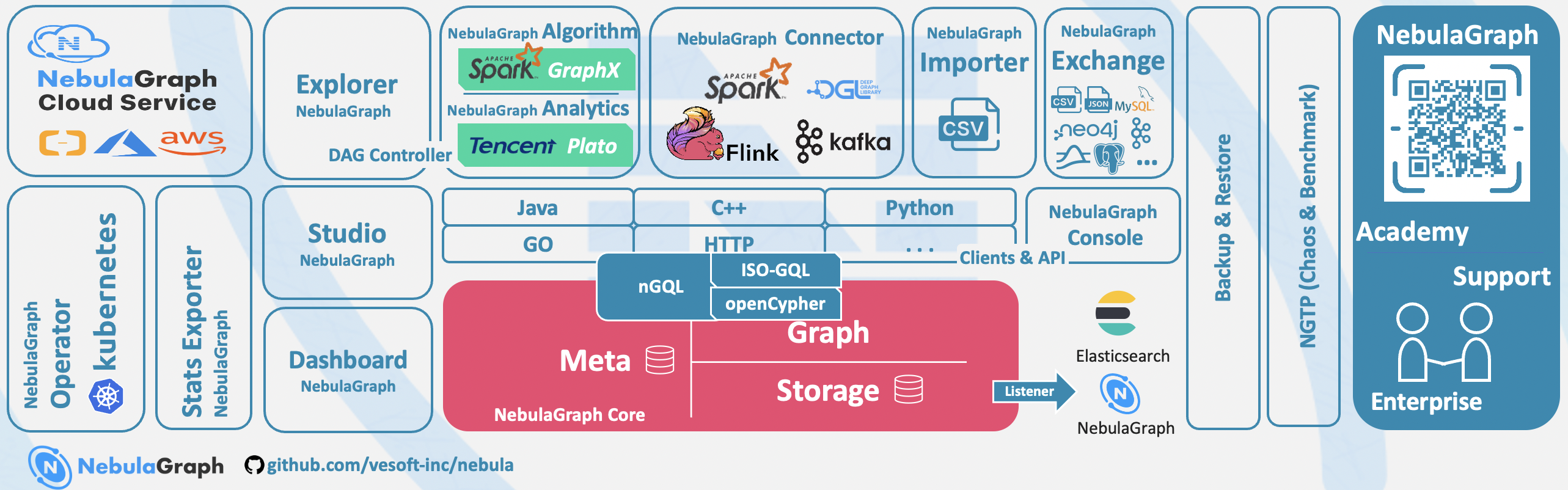
NebulaGraph Studio¶
NebulaGraph Studio (Studio for short) is a graph database visualization tool that can be accessed through the Web. It can be used with NebulaGraph DBMS to provide one-stop services such as composition, data import, writing nGQL queries, and graph exploration. For details, see What is NebulaGraph Studio.
Note
The release of the Studio is independent of NebulaGraph core, and its naming method is also not the same as the core naming rules.
| NebulaGraph version | Studio version |
|---|---|
| v3.6.0 | v3.8.0 |
NebulaGraph Dashboard Community Edition¶
NebulaGraph Dashboard Community Edition (Dashboard for short) is a visualization tool for monitoring the status of machines and services in the NebulaGraph cluster. For details, see What is NebulaGraph Dashboard.
| NebulaGraph version | Dashboard Community version |
|---|---|
| v3.6.0 | v3.4.0 |
NebulaGraph Exchange¶
NebulaGraph Exchange (Exchange for short) is an Apache Spark&trade application for batch migration of data in a cluster to NebulaGraph in a distributed environment. It can support the migration of batch data and streaming data in a variety of different formats. For details, see What is NebulaGraph Exchange.
| NebulaGraph version | Exchange Community version |
|---|---|
| v3.6.0 | v3.6.1 |
NebulaGraph Operator¶
NebulaGraph Operator (Operator for short) is a tool to automate the deployment, operation, and maintenance of NebulaGraph clusters on Kubernetes. Building upon the excellent scalability mechanism of Kubernetes, NebulaGraph introduced its operation and maintenance knowledge into the Kubernetes system, which makes NebulaGraph a real cloud-native graph database. For more information, see What is NebulaGraph Operator.
| NebulaGraph version | Operator version |
|---|---|
| v3.6.0 | v1.8.0 |
NebulaGraph Importer¶
NebulaGraph Importer (Importer for short) is a CSV file import tool for NebulaGraph. The Importer can read the local CSV file, and then import the data into the NebulaGraph database. For details, see What is NebulaGraph Importer.
| NebulaGraph version | Importer version |
|---|---|
| v3.6.0 | v4.1.0 |
NebulaGraph Spark Connector¶
NebulaGraph Spark Connector is a Spark connector that provides the ability to read and write NebulaGraph data in the Spark standard format. NebulaGraph Spark Connector consists of two parts, Reader and Writer. For details, see What is NebulaGraph Spark Connector.
| NebulaGraph version | Spark Connector version |
|---|---|
| v3.6.0 | v3.6.0 |
NebulaGraph Flink Connector¶
NebulaGraph Flink Connector is a connector that helps Flink users quickly access NebulaGraph. It supports reading data from the NebulaGraph database or writing data read from other external data sources to the NebulaGraph database. For details, see What is NebulaGraph Flink Connector.
| NebulaGraph version | Flink Connector version |
|---|---|
| v3.6.0 | v3.5.0 |
NebulaGraph Algorithm¶
NebulaGraph Algorithm (Algorithm for short) is a Spark application based on GraphX, which uses a complete algorithm tool to analyze data in the NebulaGraph database by submitting a Spark task To perform graph computing, use the algorithm under the lib repository through programming to perform graph computing for DataFrame. For details, see What is NebulaGraph Algorithm.
| NebulaGraph version | Algorithm version |
|---|---|
| v3.6.0 | v3.0.0 |
NebulaGraph Console¶
NebulaGraph Console is the native CLI client of NebulaGraph. For how to use it, see NebulaGraph Console.
| NebulaGraph version | Console version |
|---|---|
| v3.6.0 | v3.6.0 |
NebulaGraph Docker Compose¶
Docker Compose can quickly deploy NebulaGraph clusters. For how to use it, please refer to Docker Compose Deployment NebulaGraph.
| NebulaGraph version | Docker Compose version |
|---|---|
| v3.6.0 | v3.6.0 |
Backup & Restore¶
Backup&Restore (BR for short) is a command line interface (CLI) tool that can help back up the graph space data of NebulaGraph, or restore it through a backup file data.
| NebulaGraph version | BR version |
|---|---|
| v3.6.0 | v3.6.0 |
NebulaGraph Bench¶
NebulaGraph Bench is used to test the baseline performance data of NebulaGraph. It uses the standard data set of LDBC.
| NebulaGraph version | Bench version |
|---|---|
| v3.6.0 | v1.2.0 |
API, SDK¶
Compatibility
Select the latest version of X.Y.* which is the same as the core version.
| NebulaGraph version | Language |
|---|---|
| v3.6.0 | C++ |
| v3.6.0 | Go |
| v3.6.0 | Python |
| v3.6.0 | Java |
| v3.6.0 | HTTP |
Community contributed tools¶
The following are useful utilities and tools contributed and maintained by community users.
- Object Relational Mapping (ORM) frameworks
- NGBATIS: An ORM framework that integrates with the Spring Boot ecosystem
- graph-ocean: An ORM framework developed based on NebulaGraph Java client
- nebula-jdbc: An ORM framework that supports JDBC
- nebula-carina: An ORM framework developed based on NebulaGraph Python client
- norm: An ORM framework written in Golang
- Data processing tools
- nebula-real-time-exchange: Enables real-time data synchronization from MySQL to NebulaGraph
- nebula-datax-plugin: Provides NebulaGraph's Reader and Writer plugins based on DataX to enable offline data synchronization
- Quick deployment
- nebulagraph-docker-ext: Starts NebulaGraph in Docker Desktop in 10 seconds
- nebulagraph-lite: A NebulaGraph sandbox running in the browser
- Testing
- testcontainers-nebula: A lightweight database testing library for Java
- Clients
- zio-nebula: Scala client
- nebula-node: Node.js client
- nebula-php: PHP client
- nebula-net: .NET client
- nebula-rust: Rust client
- Terminal tools
- nebula-console-intellij-plugin: A Nebula-console plugin for JetBrains IDEs that supports syntax highlighting, function field auto-completion, data table pagination, and relationship graphs.