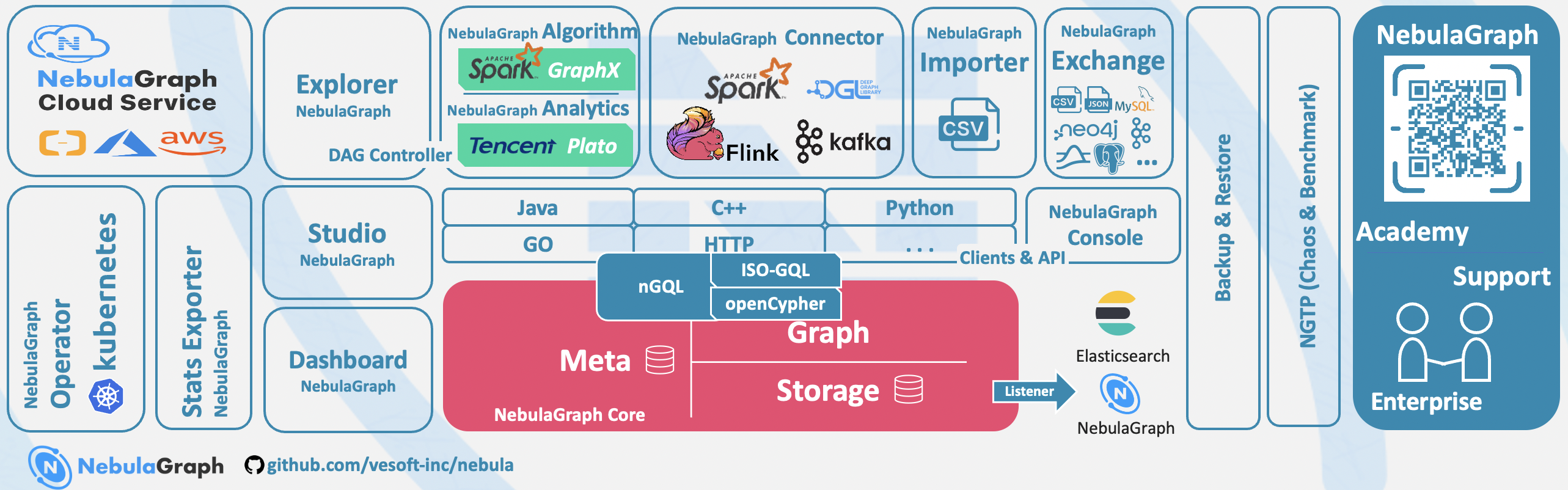
Ecosystem tools overview¶
Compatibility
The core release number naming rule is X.Y.Z, which means Major version X, Medium version Y, and Minor version Z. The upgrade requirements for the client are:
- Upgrade the core from
X.Y.Z1toX.Y.Z2: It means that the core is fully forward compatible and is usually used for bugfixes. It is recommended to upgrade the minor version of the core as soon as possible. At this time, the client can stay not upgraded.
- Upgrade the core from
X.Y1.*toX.Y2.*: It means that there is some incompatibility of API, syntax, and return value. It is usually used to add functions, improve performance, and optimize code. The client needs to be upgraded toX.Y2.*.
- Upgrade the core from
X1.*.*toX2.*.*: It means that there is a major incompatibility in storage formats, API, syntax, etc. You need to use tools to upgrade the core data. The client must be upgraded.
- The default core and client do not support downgrade: You cannot downgrade from
X.Y.Z2toX.Y.Z1.
- The release cycle of a
Yversion is about 6 months, and its maintenance and support cycle is 6 months.
- The version released at the beginning of the year is usually named
X.0.0, and in the middle of the year, it is namedX.5.0.
- The file name contains
RCto indicate an unofficial version (Release Candidate) that is only used for preview. Its maintenance period is only until the next RC or official version is released. Its client, data compatibility, etc. are not guaranteed.
- The files with
nightly,SNAPSHOT, or date are the nightly versions. There is no quality assurance and maintenance period.
NebulaGraph Studio¶
NebulaGraph Studio (Studio for short) is a graph database visualization tool that can be accessed through the Web. It can be used with NebulaGraph DBMS to provide one-stop services such as composition, data import, writing nGQL queries, and graph exploration. For details, see What is NebulaGraph Studio.
Note
The release of the Studio is independent of NebulaGraph core, and its naming method is also not the same as the core naming rules.
| NebulaGraph version | Studio version |
|---|---|
| v3.3.0 | v3.5.1 |
NebulaGraph Dashboard Community Edition¶
NebulaGraph Dashboard Community Edition (Dashboard for short) is a visualization tool for monitoring the status of machines and services in the NebulaGraph cluster. For details, see What is NebulaGraph Dashboard.
| NebulaGraph version | Dashboard Community version |
|---|---|
| v3.3.0 | v3.2.0 |
NebulaGraph Dashboard Enterprise Edition¶
NebulaGraph Dashboard Enterprise Edition (Dashboard for short) is a visualization tool that monitors and manages the status of machines and services in NebulaGraph cluster. For details, see What is NebulaGraph Dashboard.
| NebulaGraph version | Dashboard Enterprise version |
|---|---|
| v3.3.0 | v3.2.4 |
NebulaGraph Explorer¶
NebulaGraph Explorer (Explorer for short) is a graph exploration visualization tool that can be accessed through the Web. It is used with the NebulaGraph core to visualize interaction with graph data. Users can quickly become map experts, even without experience in map data manipulation. For details, see What is NebulaGraph Explorer.
| NebulaGraph version | Explorer Enterprise version |
|---|---|
| v3.3.0 | v3.2.1 |
NebulaGraph Stats Exporter¶
Nebula-stats-exporter exports monitor metrics to Promethus.
| NebulaGraph version | Stats Exporter version |
|---|---|
| v3.3.0 | v3.3.0 |
NebulaGraph Exchange¶
NebulaGraph Exchange (Exchange for short) is an Apache Spark&trade application for batch migration of data in a cluster to NebulaGraph in a distributed environment. It can support the migration of batch data and streaming data in a variety of different formats. For details, see What is NebulaGraph Exchange.
| NebulaGraph version | Exchange Community version | Exchange Enterprise version |
|---|---|---|
| v3.3.0 | v3.3.0 | v3.0.0 |
NebulaGraph Operator¶
NebulaGraph Operator (Operator for short) is a tool to automate the deployment, operation, and maintenance of NebulaGraph clusters on Kubernetes. Building upon the excellent scalability mechanism of Kubernetes, NebulaGraph introduced its operation and maintenance knowledge into the Kubernetes system, which makes NebulaGraph a real cloud-native graph database. For more information, see What is NebulaGraph Operator.
| NebulaGraph version | Operator version |
|---|---|
| v3.3.0 | v1.3.0 |
NebulaGraph Importer¶
NebulaGraph Importer (Importer for short) is a CSV file import tool for NebulaGraph. The Importer can read the local CSV file, and then import the data into the NebulaGraph database. For details, see What is NebulaGraph Importer.
| NebulaGraph version | Importer version |
|---|---|
| v3.3.0 | v3.1.0 |
NebulaGraph Spark Connector¶
NebulaGraph Spark Connector is a Spark connector that provides the ability to read and write NebulaGraph data in the Spark standard format. NebulaGraph Spark Connector consists of two parts, Reader and Writer. For details, see What is NebulaGraph Spark Connector.
| NebulaGraph version | Spark Connector version |
|---|---|
| v3.3.0 | v3.3.0 |
NebulaGraph Flink Connector¶
NebulaGraph Flink Connector is a connector that helps Flink users quickly access NebulaGraph. It supports reading data from the NebulaGraph database or writing data read from other external data sources to the NebulaGraph database. For details, see What is NebulaGraph Flink Connector.
| NebulaGraph version | Flink Connector version |
|---|---|
| v3.3.0 | v3.3.0 |
NebulaGraph Algorithm¶
NebulaGraph Algorithm (Algorithm for short) is a Spark application based on GraphX, which uses a complete algorithm tool to analyze data in the NebulaGraph database by submitting a Spark task To perform graph computing, use the algorithm under the lib repository through programming to perform graph computing for DataFrame. For details, see What is NebulaGraph Algorithm.
| NebulaGraph version | Algorithm version |
|---|---|
| v3.3.0 | v3.0.0 |
NebulaGraph Analytics¶
NebulaGraph Analytics is an application that integrates the open-source Plato Graph Computing Framework, with which NebulaGraph Analytics performs graph computations on NebulaGraph database data. For details, see What is NebulaGraph Analytics.
| NebulaGraph version | Analytics version |
|---|---|
| v3.3.0 | v3.3.0 |
NebulaGraph Console¶
NebulaGraph Console is the native CLI client of NebulaGraph. For how to use it, see NebulaGraph Console.
| NebulaGraph version | Console version |
|---|---|
| v3.3.0 | v3.3.1 |
NebulaGraph Docker Compose¶
Docker Compose can quickly deploy NebulaGraph clusters. For how to use it, please refer to Docker Compose Deployment NebulaGraph.
| NebulaGraph version | Docker Compose version |
|---|---|
| v3.3.0 | v3.3.0 |
Backup & Restore¶
Backup&Restore (BR for short) is a command line interface (CLI) tool that can help back up the graph space data of NebulaGraph, or restore it through a backup file data.
| NebulaGraph version | BR version |
|---|---|
| v3.3.0 | v3.3.0 |
NebulaGraph Bench¶
NebulaGraph Bench is used to test the baseline performance data of NebulaGraph. It uses the standard data set of LDBC.
| NebulaGraph version | Bench version |
|---|---|
| v3.3.0 | v1.2.0 |
API, SDK¶
Compatibility
Select the latest version of X.Y.* which is the same as the core version.
| NebulaGraph version | Language |
|---|---|
| v3.3.0 | C++ |
| v3.3.0 | Go |
| v3.3.0 | Python |
| v3.3.0 | Java |
| v3.3.0 | HTTP |
Not Released¶
- Rust Client
- Node.js Client
- Object Graph Mapping Library (OGM, or ORM)