Storage Service¶
The persistent data of NebulaGraph have two parts. One is the Meta Service that stores the meta-related data.
The other is the Storage Service that stores the data, which is run by the nebula-storaged process. This topic will describe the architecture of the Storage Service.
Advantages¶
- High performance (Customized built-in KVStore)
- Great scalability (Shared-nothing architecture, not rely on NAS/SAN-like devices)
- Strong consistency (Raft)
- High availability (Raft)
- Supports synchronizing with the third party systems, such as Elasticsearch.
The architecture of the Storage Service¶
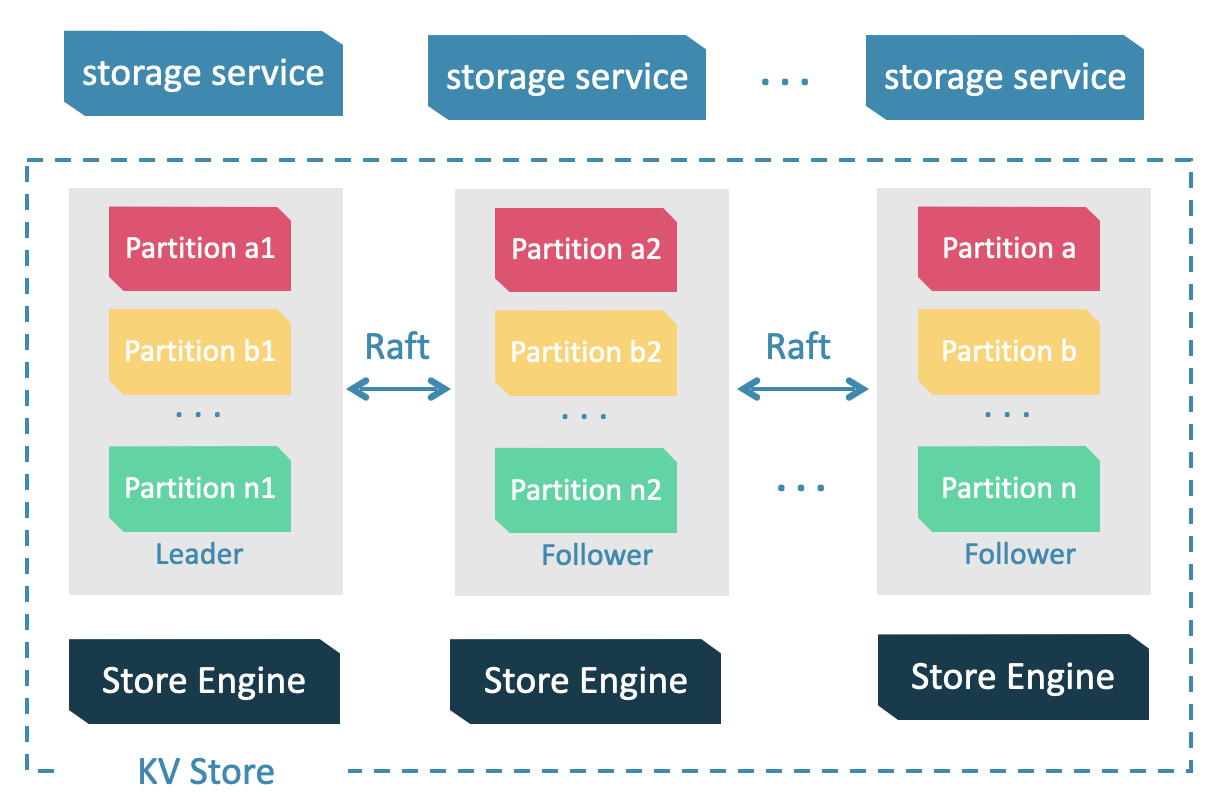
The Storage Service is run by the nebula-storaged process. Users can deploy nebula-storaged processes on different occasions. For example, users can deploy 1 nebula-storaged process in a test environment and deploy 3 nebula-storaged processes in a production environment.
All the nebula-storaged processes consist of a Raft-based cluster. There are three layers in the Storage Service:
-
Storage interface
The top layer is the storage interface. It defines a set of APIs that are related to the graph concepts. These API requests will be translated into a set of KV operations targeting the corresponding Partition. For example:
getNeighbors: queries the in-edge or out-edge of a set of vertices, returns the edges and the corresponding properties, and supports conditional filtering.
insert vertex/edge: inserts a vertex or edge and its properties.
getProps: gets the properties of a vertex or an edge.
It is this layer that makes the Storage Service a real graph storage. Otherwise, it is just a KV storage.
-
Consensus
Below the storage interface is the consensus layer that implements Multi Group Raft, which ensures the strong consistency and high availability of the Storage Service.
-
Store engine
The bottom layer is the local storage engine library, providing operations like
get,put, andscanon local disks. The related interfaces are stored inKVStore.handKVEngine.hfiles. You can develop your own local store plugins based on your needs.
The following will describe some features of the Storage Service based on the above architecture.
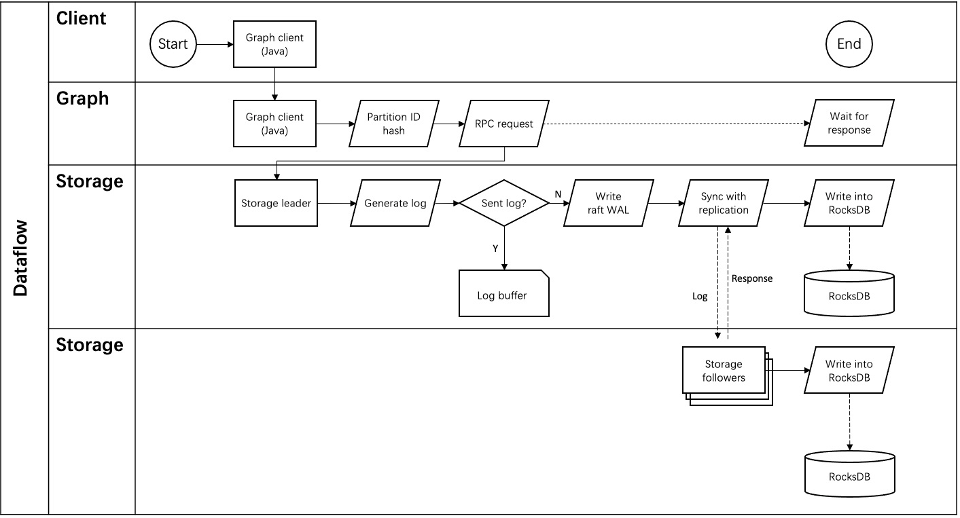
Storage writing process¶
KVStore¶
NebulaGraph develops and customizes its built-in KVStore for the following reasons.
- It is a high-performance KVStore.
- It is provided as a (kv) library and can be easily developed for the filter pushdown purpose. As a strong-typed database, how to provide Schema during pushdown is the key to efficiency for NebulaGraph.
- It has strong data consistency.
Therefore, NebulaGraph develops its own KVStore with RocksDB as the local storage engine. The advantages are as follows.
- For multiple local hard disks, NebulaGraph can make full use of its concurrent capacities through deploying multiple data directories.
-
The Meta Service manages all the Storage servers. All the partition distribution data and current machine status can be found in the meta service. Accordingly, users can execute a manual load balancing plan in meta service.
Note
NebulaGraph does not support auto load balancing because auto data transfer will affect online business.
- NebulaGraph provides its own WAL mode so one can customize the WAL. Each partition owns its WAL.
- One NebulaGraph KVStore cluster supports multiple graph spaces, and each graph space has its own partition number and replica copies. Different graph spaces are isolated physically from each other in the same cluster.
Data storage structure¶
Graphs consist of vertices and edges. NebulaGraph uses key-value pairs to store vertices, edges, and their properties. Vertices and edges are stored in keys and their properties are stored in values. Such structure enables efficient property filtering.
-
The storage structure of vertices
Different from NebulaGraph version 2.x, version 3.x added a new key for each vertex. Compared to the old key that still exists, the new key has no
TagIDfield and no value. Vertices in NebulaGraph can now live without tags owing to the new key.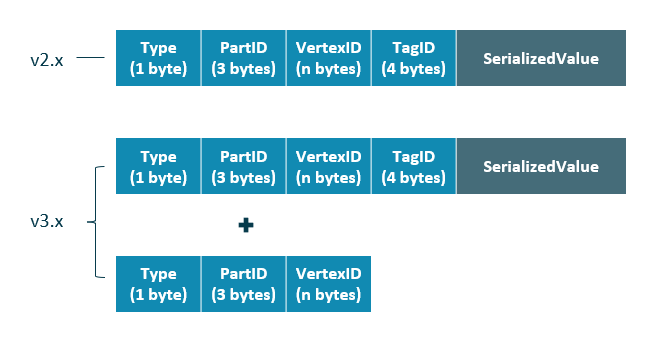
Field Description TypeOne byte, used to indicate the key type. PartIDThree bytes, used to indicate the sharding partition and to scan the partition data based on the prefix when re-balancing the partition. VertexIDThe vertex ID. For an integer VertexID, it occupies eight bytes. However, for a string VertexID, it is changed to fixed_stringof a fixed length which needs to be specified by users when they create the space.TagIDFour bytes, used to indicate the tags that vertex relate with. SerializedValueThe serialized value of the key. It stores the property information of the vertex.
- The storage structure of edges

Field Description TypeOne byte, used to indicate the key type. PartIDThree bytes, used to indicate the partition ID. This field can be used to scan the partition data based on the prefix when re-balancing the partition. VertexIDUsed to indicate vertex ID. The former VID refers to the source VID in the outgoing edge and the dest VID in the incoming edge, while the latter VID refers to the dest VID in the outgoing edge and the source VID in the incoming edge. Edge TypeFour bytes, used to indicate the edge type. Greater than zero indicates out-edge, less than zero means in-edge. RankEight bytes, used to indicate multiple edges in one edge type. Users can set the field based on needs and store weight, such as transaction time and transaction number. PlaceHolderOne byte. Reserved. SerializedValueThe serialized value of the key. It stores the property information of the edge.
Property descriptions¶
NebulaGraph uses strong-typed Schema.
NebulaGraph will store the properties of vertex and edges in order after encoding them. Since the length of properties is fixed, queries can be made in no time according to offset. Before decoding, NebulaGraph needs to get (and cache) the schema information in the Meta Service. In addition, when encoding properties, NebulaGraph will add the corresponding schema version to support online schema change.
Data partitioning¶
Since in an ultra-large-scale relational network, vertices can be as many as tens to hundreds of billions, and edges are even more than trillions. Even if only vertices and edges are stored, the storage capacity of both exceeds that of ordinary servers. Therefore, NebulaGraph uses hash to shard the graph elements and store them in different partitions.
Edge partitioning and storage amplification¶
In NebulaGraph, an edge corresponds to two key-value pairs on the hard disk. When there are lots of edges and each has many properties, storage amplification will be obvious. The storage format of edges is shown in the figure below.
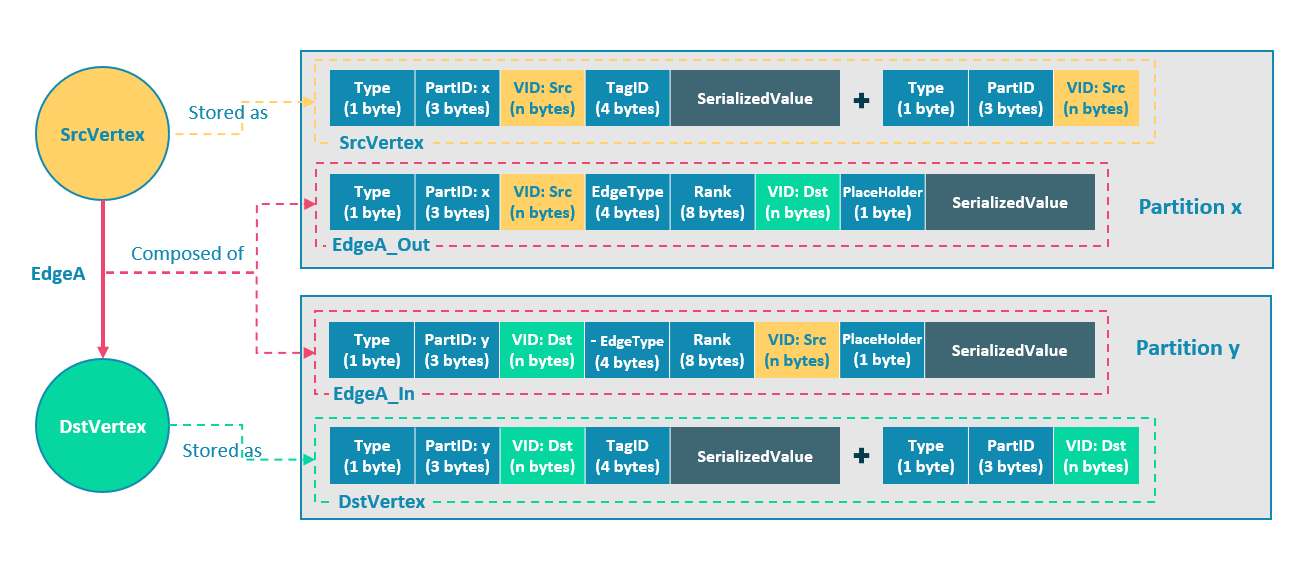
In this example, ScrVertex connects DstVertex via EdgeA, forming the path of (SrcVertex)-[EdgeA]->(DstVertex). ScrVertex, DstVertex, and EdgeA will all be stored in Partition x and Partition y as four key-value pairs in the storage layer. Details are as follows:
- The key value of SrcVertex is stored in Partition x. Key fields include Type, PartID(x), VID(Src), and TagID. SerializedValue, namely Value, refers to serialized vertex properties.
- The first key value of EdgeA, namely EdgeA_Out, is stored in the same partition as the ScrVertex. Key fields include Type, PartID(x), VID(Src), EdgeType(+ means out-edge), Rank(0), VID(Dst), and PlaceHolder. SerializedValue, namely Value, refers to serialized edge properties.
- The key value of DstVertex is stored in Partition y. Key fields include Type, PartID(y), VID(Dst), and TagID. SerializedValue, namely Value, refers to serialized vertex properties.
- The second key value of EdgeA, namely EdgeA_In, is stored in the same partition as the DstVertex. Key fields include Type, PartID(y), VID(Dst), EdgeType(- means in-edge), Rank(0), VID(Src), and PlaceHolder. SerializedValue, namely Value, refers to serialized edge properties, which is exactly the same as that in EdgeA_Out.
EdgeA_Out and EdgeA_In are stored in storage layer with opposite directions, constituting EdgeA logically. EdgeA_Out is used for traversal requests starting from SrcVertex, such as (a)-[]->(); EdgeA_In is used for traversal requests starting from DstVertex, such as ()-[]->(a).
Like EdgeA_Out and EdgeA_In, NebulaGraph redundantly stores the information of each edge, which doubles the actual capacities needed for edge storage. The key corresponding to the edge occupies a small hard disk space, but the space occupied by Value is proportional to the length and amount of the property value. Therefore, it will occupy a relatively large hard disk space if the property value of the edge is large or there are many edge property values.
To ensure the final consistency of the two key-value pairs when operating on edges, enable the TOSS function. After that, the operation will be performed in Partition x first where the out-edge is located, and then in Partition y where the in-edge is located. Finally, the result is returned. -->
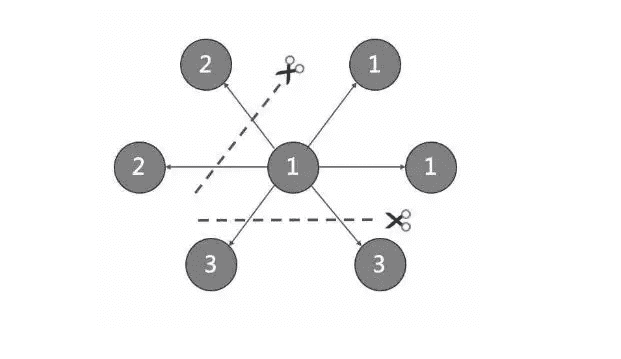
Partition algorithm¶
NebulaGraph uses a static Hash strategy to shard data through a modulo operation on vertex ID. All the out-keys, in-keys, and tag data will be placed in the same partition. In this way, query efficiency is increased dramatically.
Note
The number of partitions needs to be determined when users are creating a graph space since it cannot be changed afterward. Users are supposed to take into consideration the demands of future business when setting it.
When inserting into NebulaGraph, vertices and edges are distributed across different partitions. And the partitions are located on different machines. The number of partitions is set in the CREATE SPACE statement and cannot be changed afterward.
If certain vertices need to be placed on the same partition (i.e., on the same machine), see Formula/code.
The following code will briefly describe the relationship between VID and partition.
// If VertexID occupies 8 bytes, it will be stored in int64 to be compatible with the version 1.0.
uint64_t vid = 0;
if (id.size() == 8) {
memcpy(static_cast<void*>(&vid), id.data(), 8);
} else {
MurmurHash2 hash;
vid = hash(id.data());
}
PartitionID pId = vid % numParts + 1;
Roughly speaking, after hashing a fixed string to int64, (the hashing of int64 is the number itself), do modulo, and then plus one, namely:
pId = vid % numParts + 1;
Parameters and descriptions of the preceding formula are as follows:
| Parameter | Description |
|---|---|
% |
The modulo operation. |
numParts |
The number of partitions for the graph space where the VID is located, namely the value of partition_num in the CREATE SPACE statement. |
pId |
The ID for the partition where the VID is located. |
Suppose there are 100 partitions, the vertices with VID 1, 101, and 1001 will be stored on the same partition. But, the mapping between the partition ID and the machine address is random. Therefore, we cannot assume that any two partitions are located on the same machine.
Raft¶
Raft implementation¶
In a distributed system, one data usually has multiple replicas so that the system can still run normally even if a few copies fail. It requires certain technical means to ensure consistency between replicas.
Basic principle: Raft is designed to ensure consistency between replicas. Raft uses election between replicas, and the (candidate) replica that wins more than half of the votes will become the Leader, providing external services on behalf of all replicas. The rest Followers will play backups. When the Leader fails (due to communication failure, operation and maintenance commands, etc.), the rest Followers will conduct a new round of elections and vote for a new Leader. The Leader and Followers will detect each other's survival through heartbeats and write them to the hard disk in Raft-wal mode. Replicas that do not respond to more than multiple heartbeats will be considered faulty.
Note
Raft-wal needs to be written into the hard disk periodically. If hard disk bottlenecks to write, Raft will fail to send a heartbeat and conduct a new round of elections. If the hard disk IO is severely blocked, there will be no Leader for a long time.
Read and write: For every writing request of the clients, the Leader will initiate a Raft-wal and synchronize it with the Followers. Only after over half replicas have received the Raft-wal will it return to the clients successfully. For every reading request of the clients, it will get to the Leader directly, while Followers will not be involved.
Failure: Scenario 1: Take a (space) cluster of a single replica as an example. If the system has only one replica, the Leader will be itself. If failure happens, the system will be completely unavailable. Scenario 2: Take a (space) cluster of three replicas as an example. If the system has three replicas, one of them will be the Leader and the rest will be the Followers. If the Leader fails, the rest two can still vote for a new Leader (and a Follower), and the system is still available. But if any of the two Followers fails again, the system will be completely unavailable due to inadequate voters.
Note
Raft and HDFS have different modes of duplication. Raft is based on a quorum vote, so the number of replicas cannot be even.
Multi Group Raft¶
The Storage Service supports a distributed cluster architecture, so NebulaGraph implements Multi Group Raft according to Raft protocol. Each Raft group stores all the replicas of each partition. One replica is the leader, while others are followers. In this way, NebulaGraph achieves strong consistency and high availability. The functions of Raft are as follows.
NebulaGraph uses Multi Group Raft to improve performance when there are many partitions because Raft-wal cannot be NULL. When there are too many partitions, costs will increase, such as storing information in Raft group, WAL files, or batch operation in low load.
There are two key points to implement the Multi Raft Group:
-
To share transport layer
Each Raft Group sends messages to its corresponding peers. So if the transport layer cannot be shared, the connection costs will be very high.
-
To share thread pool
Raft Groups share the same thread pool to prevent starting too many threads and a high context switch cost.
Batch¶
For each partition, it is necessary to do a batch to improve throughput when writing the WAL serially. As NebulaGraph uses WAL to implement some special functions, batches need to be grouped, which is a feature of NebulaGraph.
For example, lock-free CAS operations will execute after all the previous WALs are committed. So for a batch, if there are several WALs in CAS type, we need to divide this batch into several smaller groups and make sure they are committed serially.
Transfer Leadership¶
Transfer leadership is extremely important for balance. When moving a partition from one machine to another, NebulaGraph first checks if the source is a leader. If so, it should be moved to another peer. After data migration is completed, it is important to balance leader distribution again.
When a transfer leadership command is committed, the leader will abandon its leadership and the followers will start a leader election.
Peer changes¶
To avoid split-brain, when members in a Raft Group change, an intermediate state is required. In such a state, the quorum of the old group and new group always have an overlap. Thus it prevents the old or new group from making decisions unilaterally. To make it even simpler, in his doctoral thesis Diego Ongaro suggests adding or removing a peer once to ensure the overlap between the quorum of the new group and the old group. NebulaGraph also uses this approach, except that the way to add or remove a member is different. For details, please refer to addPeer/removePeer in the Raft Part class.
Cache¶
The cache management of RocksDB can not cache vertices or edges on demand. NebulaGraph implements its own cache management for Storage, allowing you to set the storage cache size, content, etc. For more information, see Storage cache configurations.
Differences with HDFS¶
The Storage Service is a Raft-based distributed architecture, which has certain differences with that of HDFS. For example:
- The Storage Service ensures consistency through Raft. Usually, the number of its replicas is odd to elect a leader. However, DataNode used by HDFS ensures consistency through NameNode, which has no limit on the number of replicas.
- In the Storage Service, only the replicas of the leader can read and write, while in HDFS all the replicas can do so.
- In the Storage Service, the number of replicas needs to be determined when creating a space, since it cannot be changed afterward. But in HDFS, the number of replicas can be changed freely.
- The Storage Service can access the file system directly. While the applications of HDFS (such as HBase) have to access HDFS before the file system, which requires more RPC times.
In a word, the Storage Service is more lightweight with some functions simplified and its architecture is simpler than HDFS, which can effectively improve the read and write performance of a smaller block of data.