Market overview of graph databases¶
Now that we have discussed what a graph is, let's move on to further understanding graph databases developed based on graph theory and the property graph model.
Different graph databases may differ slightly in terms of terminology, but in the end, they all talk about vertices, edges, and properties. As for more advanced features such as labels, indexes, constraints, TTL, long tasks, stored procedures, and UDFs, these advanced features will vary significantly from one graph database to another.
Graph databases use graphs to store data, and the graph structure is one of the structures that are closest to high flexibility and high performance. A graph database is a storage engine specifically designed to store and retrieve large information, which efficiently stores data as vertices and edges and allows high-performance retrieval and querying of these vertex-edge structures. We can also add properties to these vertices and edges.
Third-party services market predictions¶
DB-Engines ranking¶
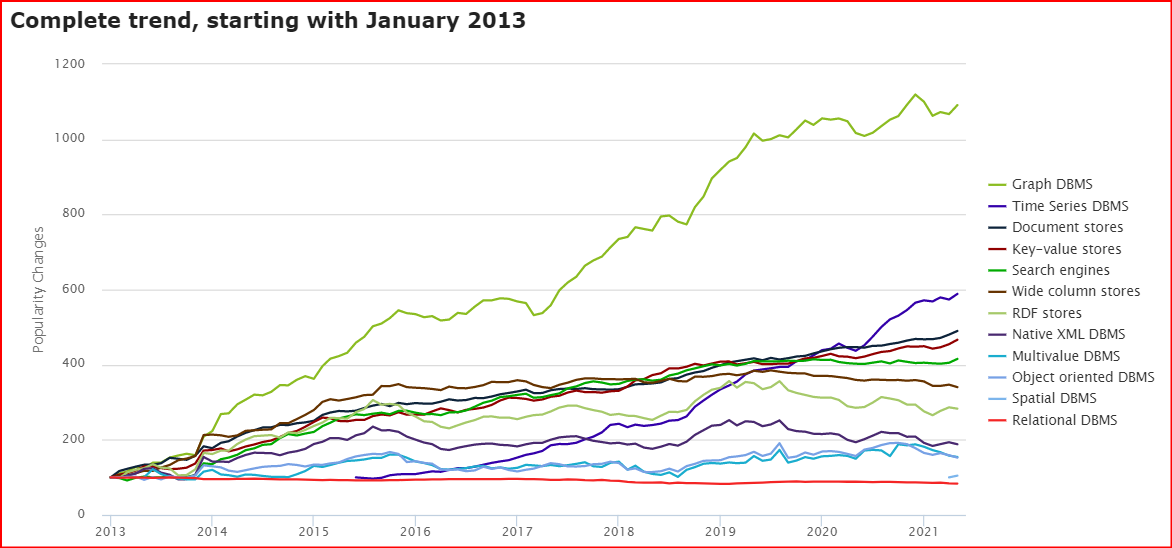
According to DB-Engines.com, the world's leading database ranking site, graph databases have been the fastest growing database category since 2013 1.
The site counts trends in the popularity of each category based on several metrics, including records and trends based on search engines such as Google, technical topics discussed on major IT technology forums and social networking sites, job posting changes on job boards. 371 database products are included in the site and are divided into 12 categories. Of these 12 categories, a category like graph databases is growing much faster than any of the others.
Gartner’s predictions¶
Gartner, one of the world's top think tanks, identified graph databases as a major business intelligence and analytics technology trend long before 2013 2. At that time, big data was hot as ever, and data scientists were in a hot position.
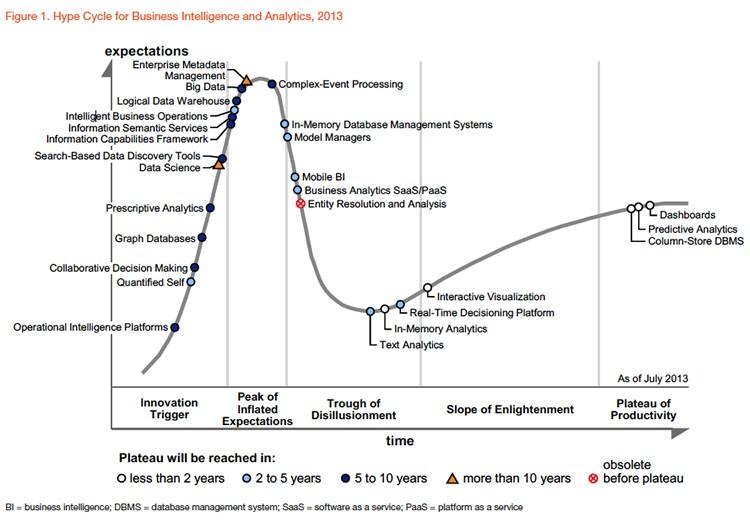
Until recently, graph databases and related graph technologies were ranked in the Top 10 Data and Analytics Trends for 2021 3.

Trend 8: Graph Relates Everything
Graphs form the foundation of many modern data and analytics capabilities to find relationships between people, places, things, events, and locations across diverse data assets. D&A leaders rely on graphs to quickly answer complex business questions which require contextual awareness and an understanding of the nature of connections and strengths across multiple entities.
Gartner predicts that by 2025, graph technologies will be used in 80% of data and analytics innovations, up from 10% in 2021, facilitating rapid decision-making across the organization.
It can be noted that Gartner's predictions match the DB-Engines ranking well. There is usually a period of rapid bubble development, then a plateau period, followed by a new bubble period due to the emergence of new technologies, and then a plateau period again.
Market size of graph databases¶
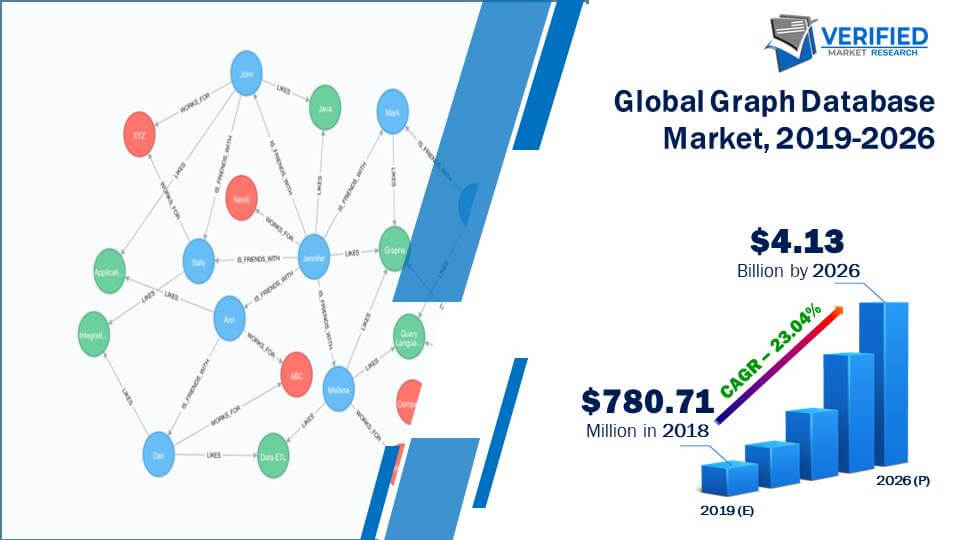
According to statistics and forecasts from Verifiedmarketresearc4, fnfresearch5, MarketsandMarkets6, and Gartner7, the global graph database market size is about to grow from about USD 0.8 billion in 2019 to USD 3-4 billion by 2026, at a Compound Annual Growth Rate (CAGR) of about 25%, which corresponds to about 5%-10% market share of the global database market.
Market participants¶
Neo4j, the pioneer of (first generation) graph databases¶
Although some graph-like data models and products, and the corresponding graph language G/G+ had been proposed in the 1970s (e.g. CODASYL 8). But it is Neo4j, the main pioneer in this market, that has really made the concept of graph databases popular, and even the two main terms (labeled) property graphs and graph databases were first introduced and practiced by Neo4j.
!!! Info "This section on the history of Neo4j and the graph query language it created, Cypher, is largely excerpted from the ISO WG3 paper An overview of the recent history of Graph Query Languages 10 and 9. To take into account the latest two years of development, the content mentioned in this topic has been abridged and updated by the authors of this book.
About GQL (Graph Query Language) and the development of an International Standard
Readers familiar with databases are probably aware of the Structured Query Language SQL. by using SQL, people access databases in a way that is close to natural language. Before SQL was widely adopted and standardized, the market for relational databases was very fragmented. Each vendor's product had a completely different way of accessing. Developers of the database product itself, developers of the tools surrounding the database product, and end-users of the database, all had to learn each product. When the SQL-89 standard was developed in 1989, the entire relational database market quickly focus on SQL-89. This greatly reduced the learning costs for the people mentioned above.
GQL (Graph Query Language) assumes a role similar to SQL in the field of graph databases. Uses interacts with graphs with GQL. Unlike international standards such as SQL-89, there are no international standards for GQL. Two mainstream graph languages are Neo4j’s Cypher and Apache TinkerPop's Gremlin. The former is often referred to as the DQL, Declarative Query Language. DQL tells the system "what to do", regardless of "how to do". The latter is referred to as the IQL, Imperative Query Language. IQL explicitly specifies the system's actions.
The GQL International Standard is in the process of being developed.
Overview of the recent history of graph databases¶
- In 2000, the idea of modeling data as a network came to the founders of Neo4j.
- In 2001, Neo4j developed the earliest core part of the code.
- In 2007, Neo4j started operating as a company.
- In 2009, Neo4j borrowed XPath as a graph query language. Gremlin 11 is also similar to XPath.
- In 2010, Marko Rodriguez, a Neo4j employee, used the term Property Graph to describe the data model of Neo4j and TinkerPop (Gremlin).
- In 2011, the first public version Neo4j 1.4 was released, and the first version of Cypher was released.
- In 2012, Neo4j 1.8 enabled you to write a Cypher. Neo4j 2.0 added labels and indexes. Cypher became a declarative graph query language.
- In 2015, Cypher was opened up by Neo4j through the openCypher project.
- In 2017, the ISO WG3 organization discussed how to use SQL to query property graph data.
- In 2018, Starting from the Neo4j 3.5 GA, the core of Neo4j only for the Enterprise Edition will no longer be open source.
- In 2019, ISO officially established two projects ISO/IEC JTC 1 N 14279 and ISO/IEC JTC 1/SC 32 N 3228 to develop an international standard for graph database language.
- In 2021, the $325 million Series F funding round for Neo4j marks the largest investment round in database history.
The early history of Neo4j¶
The data model property graph was first conceived in 2000. The founders of Neo4j were developing a media management system, and the schema of the system was often changed. To adapt to such changes, Peter Neubauer, one of the founders, wanted to enable the system to be modeled to a conceptually interconnected network. A group of graduate students at the Indian Institute of Technology Bombay implemented the earliest prototypes. Emil Eifrém, the Neo4j co-founder, and these students spent a week extending Peter's idea into a more abstract model: vertices were connected by relationships, and key-values were used as properties of vertices and relationships. They developed a Java API to interact with this data model and implemented an abstraction layer on top of the relational database.
Although this network model greatly improved productivity, its performance has been poor. So Johan Svensson, Neo4j co-founder, put a lot of effort into implementing a native data management system, that is Neo4j. For the first few years, Neo4j was successful as an in-house product. In 2007, the intellectual property of Neo4j was transferred to an independent database company.
In the first public release of Neo4j ( Neo4j 1.4, 2011), the data model was consisted of vertices and typed edges. Vertices and edges have properties. The early versions of Neo4j did not have indexes. Applications had to construct their search structure from the root vertex. Because this was very unwieldy for the applications, Neo4j 2.0 (2013.12) introduced a new concept label on vertices. Based on labels, Neo4j can index some predefined vertex properties.
"Vertex", "Relationship", "Property", "Relationships can only have one label.", "Vertices can have zero or multiple labels.". All these concepts form the data model definitions for Neo4j property graphs. With the later addition of indexing, Cypher became the main way of interacting with Neo4j. This is because the application developer only needs to focus on the data itself, not on the search structure that the developer built himself as mentioned above.
The creation of Gremlin¶
Gremlin is a graph query language based on Apache TinkerPop, which is close in style to a sequence of function (procedure) calls. Initially, Neo4j was queried through the Java API. applications could embed the query engine as a library into the application and then use the API to query the graph.
The early Neo4j employees Tobias Lindaaker, Ivarsson, Peter Neubauer, and Marko Rodriguez used XPath as a graph query. Groovy provides loop structures, branching, and computation. This was the original prototype of Gremlin, the first version of which was released in November 2009.
Later, Marko found a lot of problems with using two different parsers (XPath and Groovy) at the same time and changed Gremlin to a Domain Specific Language (DSL) based on Groovy.
The creation of Cypher¶
Gremlin, like Neo4j's Java API, was originally intended to be a procedural way of expressing how to query databases. It uses shorter syntaxes to query and remotely access databases through the network. The procedural nature of Gremlin requires users to know the best way to query results, which is still burdensome for application developers. Over the last 30 years, the declarative language SQL has been a great success. SQL can separate the declarative way to get data from how the engine gets data. So the Neo4j engineers wanted to develop a declarative graph query language.
In 2010, Andrés Taylor joined Neo4j as an engineer. Inspired by SQL, he started a project to develop graph query language, which was released as Neo4j 1.4 in 2011. The language is the ancestor of most graph query languages today - Cypher.
Cypher's syntax is based on the use of ASCII art to describe graph patterns. This approach originally came from the annotations on how to describe graph patterns in the source code. An example can be seen as follows.
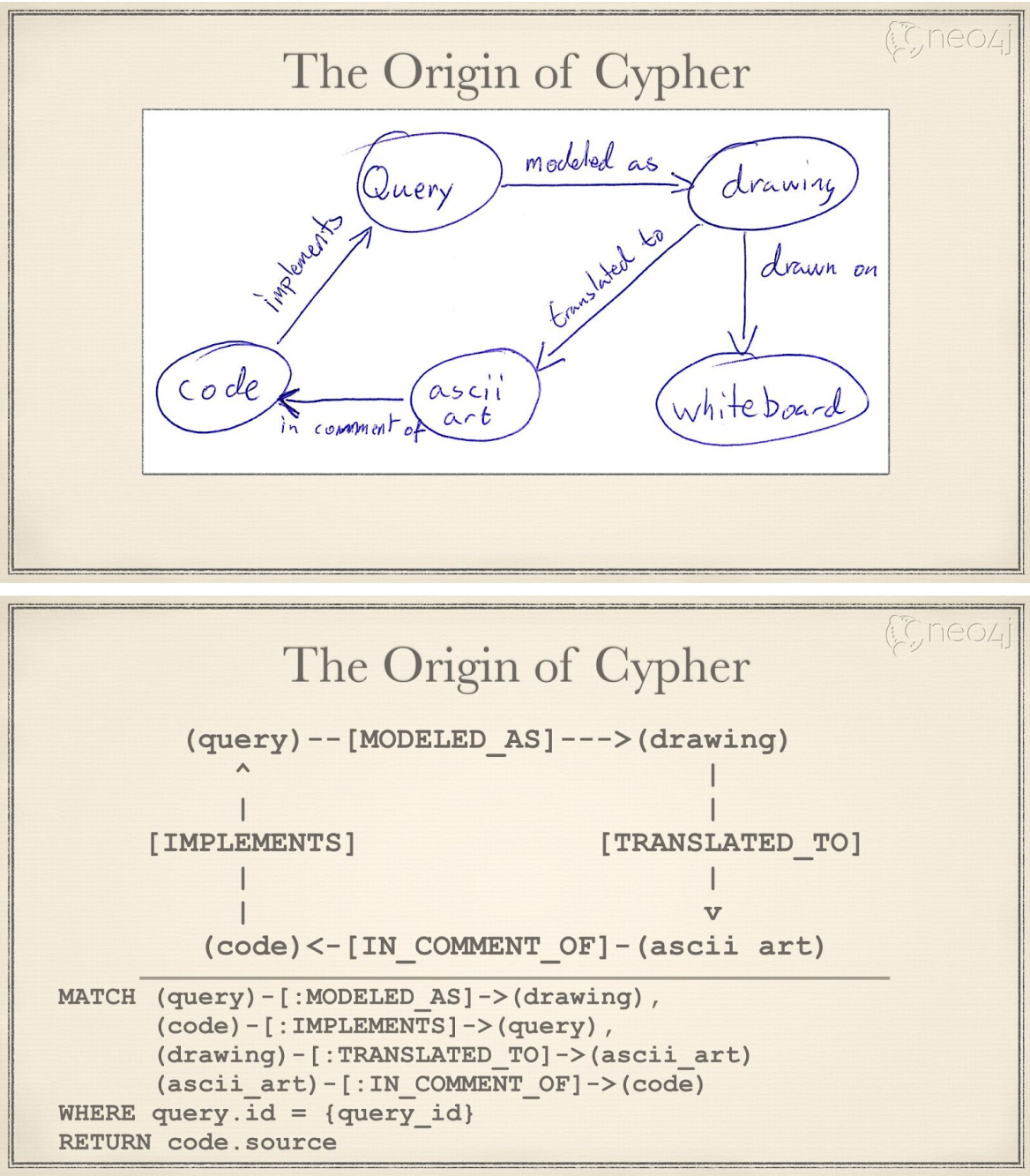
Simply put, ASCII art uses printable text to describe vertices and edges. Cypher syntax uses () for vertices and -[]-> for edges. (query)-[modeled as]->(drawing) is used to represent a simple graph relationship (which can also be called graph schema): the starting vertex - query, the destination vertex - drawing, and the edge - modeled as.
The first version of Cypher implemented graph reading, but users should specify vertices from which to start querying. Only from these vertices could graph schema matching be supported.
In a later version, Neo4j 1.8, released in October 2012, Cypher added the ability to modify graphs. However, queries still need to specify which nodes to start from.
In December 2013, Neo4j 2.0 introduced the concept of a label, which is essentially an index. This allows the query engine to use the index to select the vertices matched by the schema, without requiring the user to specify the vertex to start the query.
With the popularity of Neo4j, Cypher has a wide community of developers and is widely used in a variety of industries. It is still the most popular graph query language.
In September 2015, Neo4j established the openCypher Implementors Group (oCIG) to open source Cypher to openCypher, to govern and advance the evolution of the language itself through open source.
Subsequent events¶
Cypher has inspired a series of graph query languages, including:
2015, Oracle released PGQL, a graph language used by the graph engine PGX.
2016, the Linked Data Benchmarking Council (short for LDBC) an industry-renowned benchmarking organization for graph performance, released G-CORE.
2018, RedisGraph, a Redis-based graph library, adopted Cypher as its graph language.
2019, the International Standards Organization ISO started two projects to initiate the process of developing an international standard for graph languages based on existing industry achievements such as openCypher, PGQL, GSQL12, and G-CORE.
2019, NebulaGraph released NebulaGraph Query Language (nGQL) based on openCypher.

Distributed graph databases¶
From 2005 to 2010, with the release of Google's cloud computing "Troika", various distributed architectures became increasingly popular, including Hadoop and Cassandra, which have been open-sourced. Several implications are as follows:
-
The technical and cost advantages of distributed systems over single machines (e.g. Neo4j) or small machines are more obvious due to the increasing volume of data and computation. Distributed systems allow applications to access these thousands of machines as if they were local systems, without the need for much modification at the code level.
-
The open-source approach allows more people to know emerging technologies and feedback to the community in a more cost-effective way, including code developers, data scientists, and product managers.
Strictly speaking, Neo4j also offers several distributed capabilities, which are quite different from the industry's sense of the distributed system.
-
Neo4j 3. x requires that the full amount of data must be stored on a single machine. Although it supports full replication and high availability between multiple machines, the data cannot be sliced into different subgraphs.
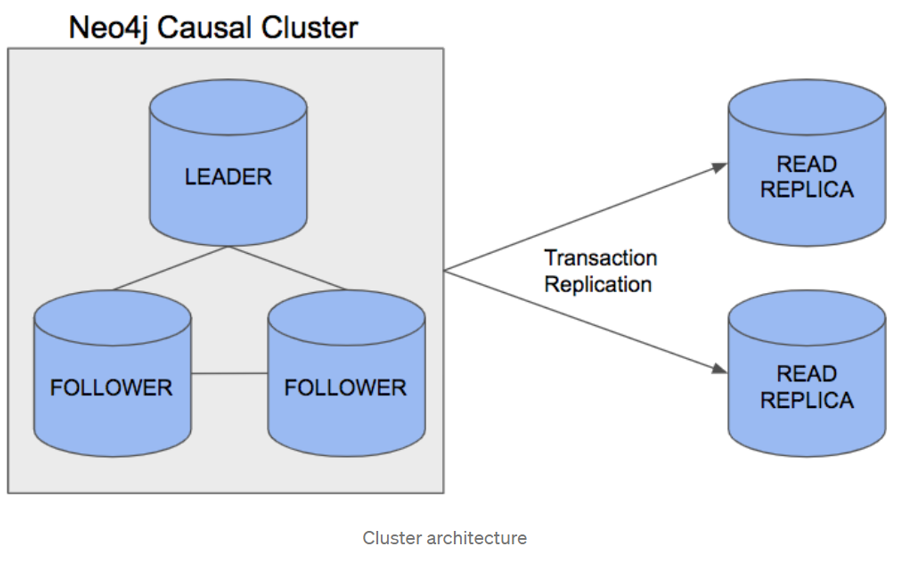
-
Neo4j 4. x stores a part of data on different machines (subgraphs), and then the application layer assembles data in a certain way (called Fabric)13 and distributes the reads and writes to each machine. This approach requires a log of involvement and work from the application layer code. For example, designing how to place different subgraphs on which machines they should be placed and how to assemble some of the results obtained from each machine into the final result.

The style of its syntax is as follows:
USE graphA MATCH (movie:Movie) Return movie.title AS title UNION USE graphB MATCH (move:Movie) RETURN movie.title AS title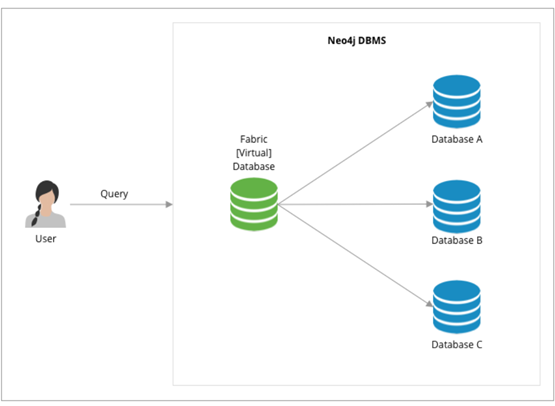
The second generation (distributed) graph database: Titan and its successor JanusGraph¶
In 2011, Aurelius was founded to develop an open-source distributed graph database called Titan 14. By the first official release of Titan in 2015, the backend of Titan can support many major distributed storage architectures (e.g. Cassandra, HBase, Elasticsearch, BerkeleyDB) and can reuse many of the conveniences of the Hadoop ecosystem, with Gremlin as a unified query language on the frontend. It is easy for programmers to use, develop and participate in the community. Large-scale graphs could be sharded and stored on HBase or Cassandra (which were relatively mature distributed storage solutions at the time), and the Gremlin language was relatively full-featured though slightly lengthy. The whole solution was competitive at that time (2011-2015).
The following picture shows the growth of Titan and Neo4j stars on Github.com from 2012 to 2015.
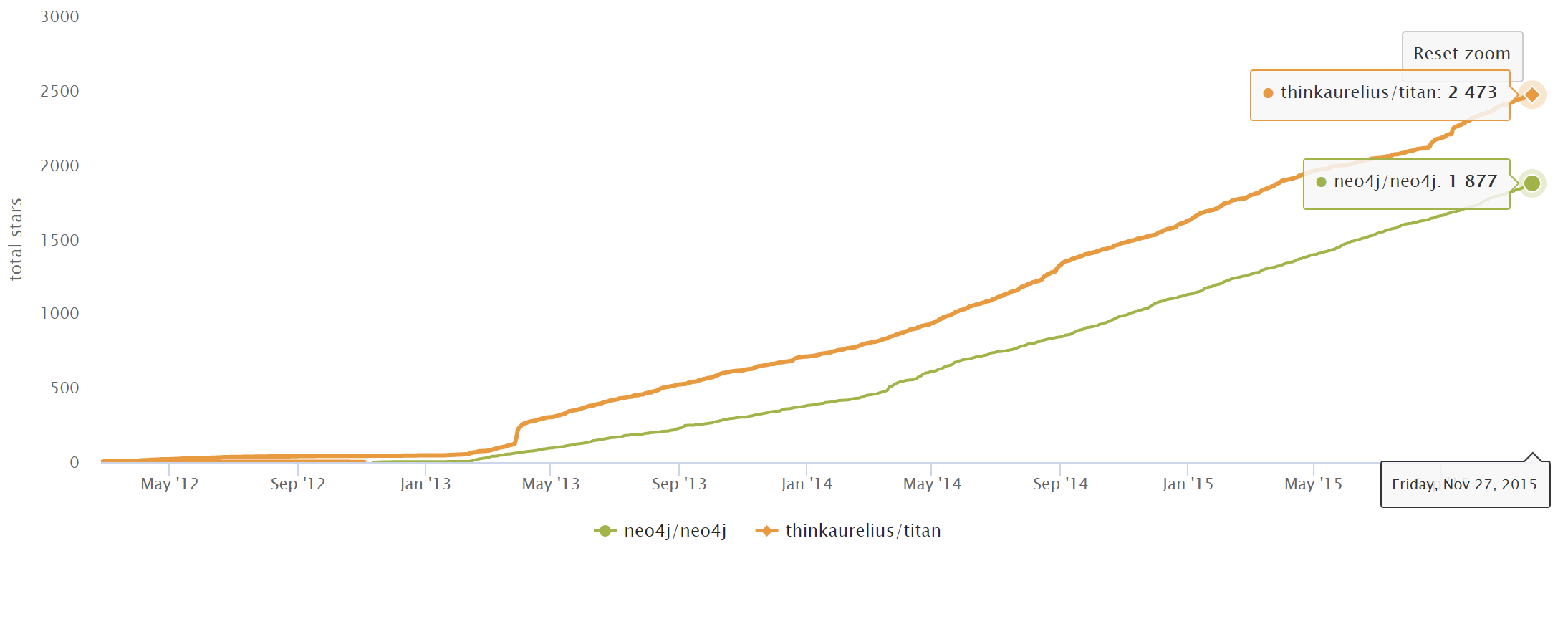
After Aurelius (Titan) was acquired by DataStax in 2015, Titan was gradually transformed into a closed-source commercial product(DataStax Enterprise Graph).
After the acquisition of Aurelius(Titan), there has been a strong demand for an open-source distributed graph database, and there were not many mature and active products in the market. In the era of big data, data is still being generated in a steady stream, far faster than Moore's Law. The Linux Foundation, along with some technology giants (Expero, Google, GRAKN.AI, Hortonworks, IBM, and Amazon) replicated and forked the original Titan project and started it as a new project JanusGraph15. Most of the community work including development, testing, release, and promotion, has been gradually shifted to the new JanusGraph.
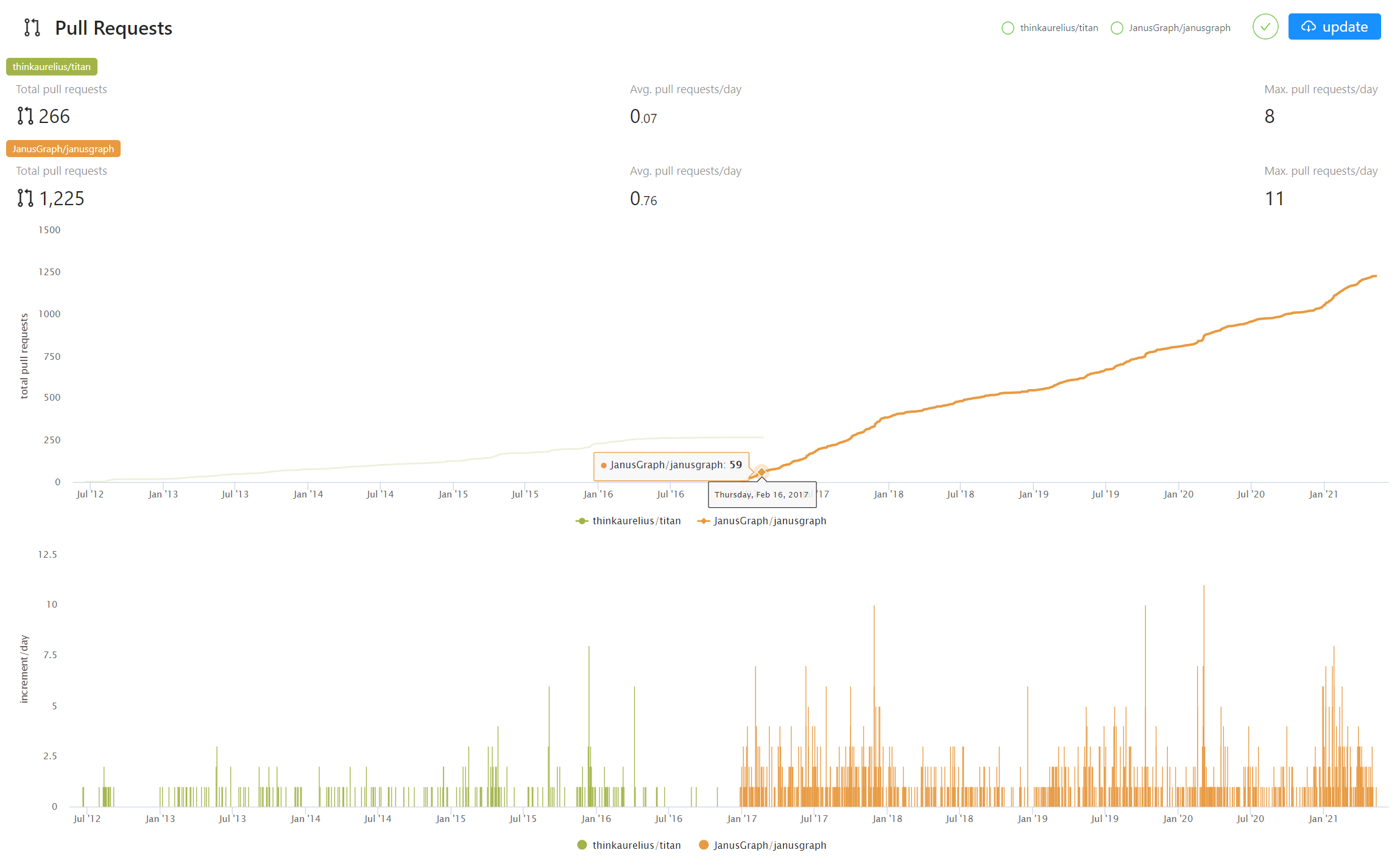
The following graph shows the evolution of daily code commits (pull requests) for the two projects, and we can see:
-
Although Aurelius(Titan) still has some activity in its open-source code after its acquisition in 2015, the growth rate has slowed down significantly. This reflects the strength of the community.
-
After the new project was started in January 2017, its community became active quickly, surpassing the number of pull requests accumulated by Titan in the past 5 years in just one year. At the same time, the open-source Titan came to a halt.
Famous products of the same period OrientDB, TigerGraph, ArangoDB, and DGraph¶
In addition to JanusGraph managed by the Linux Foundation, more vendors have been joined the overall market. Some distributed graph databases that were developed by commercial companies use different data models and access methods.
The following table only lists the main differences.
| Vendors | Creation time | Core product | Open source protocol | Data model | Query language |
|---|---|---|---|---|---|
| OrientDB LTD (Acquired by SAP in 2017) | 2011 | OrientDB | Open source | Document + KV + Graph | OrientDB SQL (SQL-based extended graph abilities) |
| GraphSQL (was renamed TigerGraph) | 2012 | TigerGraph | Commercial version | Graph (Analysis) | GraphSQL (similar to SQL) |
| ArangoDB GmbH | 2014 | ArangoDB | Apache License 2.0 | Document + KV + Graph | AQL (Simultaneous operation of documents, KVs and graphs) |
| DGraph Labs | 2016 | DGraph | Apache Public License 2.0 + Dgraph Community License | Originally RDF, later changed to GraphQL | GraphQL+- |
Traditional giants Microsoft, Amazon, and Oracle¶
In addition to vendors focused on graph products, traditional giants have also entered the graph database field.
Microsoft Azure Cosmos DB16 is a multimodal database cloud service on the Microsoft cloud that provides SQL, document, graph, key-value, and other capabilities. Amazon AWS Neptune17 is a graph database cloud service provided by AWS support property graphs and RDF two data models. Oracle Graph18 is a product of the relational database giant Oracle in the direction of graph technology and graph databases.
NebulaGraph, a new generation of open-source distributed graph databases¶
In the following topics, we will formally introduce NebulaGraph, a new generation of open-source distributed graph databases.
-
https://db-engines.com/en/ranking_categories ↩
-
https://www.yellowfinbi.com/blog/2014/06/yfcommunitynews-big-data-analytics-the-need-for-pragmatism-tangible-benefits-and-real-world-case-165305 ↩
-
https://www.gartner.com/smarterwithgartner/gartner-top-10-data-and-analytics-trends-for-2021/ ↩
-
https://www.verifiedmarketresearch.com/product/graph-database-market/ ↩
-
https://www.globenewswire.com/news-release/2021/01/28/2165742/0/en/Global-Graph-Database-Market-Size-Share-to-Exceed-USD-4-500-Million-By-2026-Facts-Factors.html ↩
-
https://www.marketsandmarkets.com/Market-Reports/graph-database-market-126230231.html ↩
-
https://www.gartner.com/en/newsroom/press-releases/2019-07-01-gartner-says-the-future-of-the-database-market-is-the ↩
-
https://www.amazon.com/Designing-Data-Intensive-Applications-Reliable-Maintainable/dp/1449373321 ↩
-
I. F. Cruz, A. O. Mendelzon, and P. T. Wood. A Graphical Query Language Supporting Recursion. In Proceedings of the Association for Computing Machinery Special Interest Group on Management of Data, pages 323–330. ACM Press, May 1987. ↩
-
"An overview of the recent history of Graph Query Languages". Authors: Tobias Lindaaker, U.S. National Expert.Date: 2018-05-14 ↩
-
Gremlin is a graph language developed based on Apache TinkerPop. ↩
-
https://docs.tigergraph.com/dev/gsql-ref ↩
-
https://neo4j.com/fosdem20/ ↩
-
https://github.com/thinkaurelius/titan ↩
-
https://github.com/JanusGraph/janusgraph ↩
-
https://azure.microsoft.com/en-us/free/cosmos-db/ ↩
-
https://aws.amazon.com/cn/neptune/ ↩
-
https://www.oracle.com/database/graph/ ↩