Graph Service¶
Graph Service is used to process the query. It has four submodules: Parser, Validator, Planner, and Executor. This topic will describe Graph Service accordingly.
The architecture of Graph Service¶
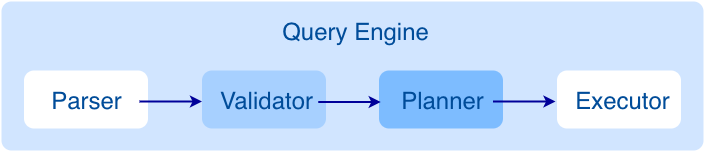
After a query is sent to Graph Service, it will be processed by the following four submodules:
-
Parser: Performs lexical analysis and syntax analysis.
-
Validator: Validates the statements.
-
Planner: Generates and optimizes the execution plans.
-
Executor: Executes the operators.
Parser¶
After receiving a request, the statements will be parsed by the Parser composed of Flex (lexical analysis tool) and Bison (syntax analysis tool), and its corresponding AST will be generated. Statements will be directly intercepted in this stage because of its invalid syntax.
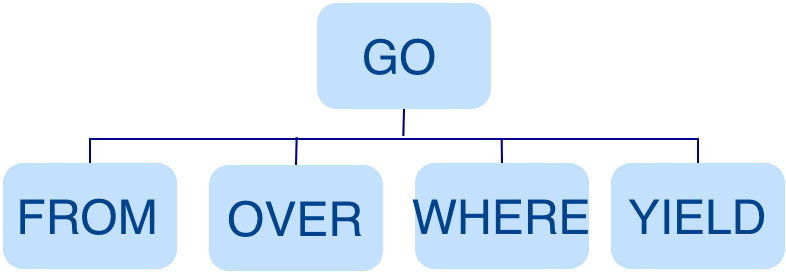
For example, the structure of the AST of GO FROM "Tim" OVER like WHERE like.likeness > 8.0 YIELD like._dst is shown in the following picture.
Validator¶
Validator performs a series of validations on the AST. It mainly works on these tasks:
- Validating metadata
Validator will validate whether the metadata is correct or not.
When parsing the
OVER,WHERE, andYIELDclauses, Validator looks up the Schema and verifies whether the edge type and tag data exist or not. For anINSERTstatement, Validator verifies whether the types of the inserted data are the same as the ones defined in the Schema.
- Validating contextual reference
Validator will verify whether the cited variable exists or not, or whether the cited property is variable or not.
For composite statements, like
$var = GO FROM "Tim" OVER like YIELD like._dst AS ID; GO FROM $var.ID OVER serve YIELD serve._dst, Validator verifies first to see ifvaris defined, and then to check if theIDproperty is attached to thevarvariable.
- Validating type inference
Validator infers what type the result of an expression is and verifies the type against the specified clause.
For example, the
WHEREclause requires the result to be aboolvalue, aNULLvalue, orempty.
- Validating the information of
*Validator needs to verify all the Schema that involves
*when verifying the clause if there is a*in the statement.Take a statement like
GO FROM "Tim" OVER * YIELD like._dst, like.likeness, serve._dstas an example. When verifying theOVERclause, Validator needs to verify all the edge types. If the edge type includeslikeandserve, the statement would beGO FROM "Tim" OVER like,serve YIELD like._dst, like.likeness, serve._dst.
- Validating input and output
Validator will check the consistency of the clauses before and after the
|.In the statement
GO FROM "Tim" OVER like YIELD like._dst AS ID | GO FROM $-.ID OVER serve YIELD serve._dst, Validator will verify whether$-.IDis defined in the clause before the|.
When the validation succeeds, an execution plan will be generated. Its data structure will be stored in the src/planner directory.
Planner¶
In the nebula-graphd.conf file, when enable_optimizer is set to be false, Planner will not optimize the execution plans generated by Validator. It will be executed by Executor directly.
In the nebula-graphd.conf file, when enable_optimizer is set to be true, Planner will optimize the execution plans generated by Validator. The structure is as follows.
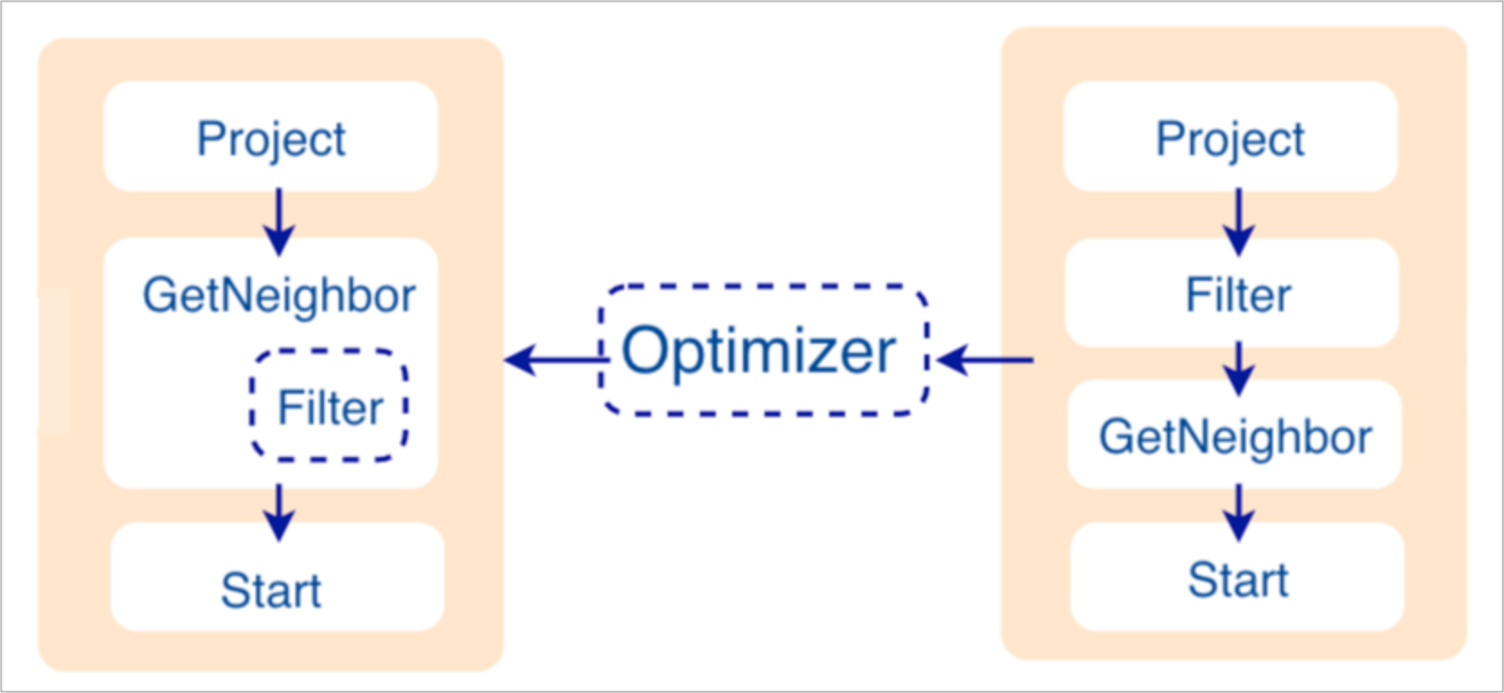
- Before optimization
In the execution plan on the right side of the preceding picture, each node directly depends on other nodes. For example, the root node
Projectdepends on theFilternode, theFilternode depends on theGetNeighbornode, and so on, up to the leaf nodeStart. Then the execution plan is (not truly) executed.During this stage, every node has its input and output variables, which are stored in a hash table. The execution plan is not truly executed, so the value of each key in the associated hash table is empty (except for the
Startnode, where the input variables hold the starting data), and the hash table is defined insrc/context/ExecutionContext.cppunder thenebula-graphrepository.For example, if the hash table is named as
ResultMapwhen creating theFilternode, users can determine that the node takes data fromResultMap["GN1"], then puts the result intoResultMap["Filter2"], and so on. All these work as the input and output of each node.
- Process of optimization
The optimization rules that Planner has implemented so far are considered RBO (Rule-Based Optimization), namely the pre-defined optimization rules. The CBO (Cost-Based Optimization) feature is under development. The optimized code is in the
src/optimizer/directory under thenebula-graphrepository.RBO is a “bottom-up” exploration process. For each rule, the root node of the execution plan (in this case, the
Projectnode) is the entry point, and step by step along with the node dependencies, it reaches the node at the bottom to see if it matches the rule.As shown in the preceding figure, when the
Filternode is explored, it is found that its children node isGetNeighbors, which matches successfully with the pre-defined rules, so a transformation is initiated to integrate theFilternode into theGetNeighborsnode, theFilternode is removed, and then the process continues to the next rule. Therefore, when theGetNeighboroperator calls interfaces of the Storage layer to get the neighboring edges of a vertex during the execution stage, the Storage layer will directly filter out the unqualified edges internally. Such optimization greatly reduces the amount of data transfer, which is commonly known as filter pushdown.
Note
Nebula Graph 2.5.0 will not run optimization by default.
Executor¶
The Executor module consists of Scheduler and Executor. The Scheduler generates the corresponding execution operators against the execution plan, starting from the leaf nodes and ending at the root node. The structure is as follows.
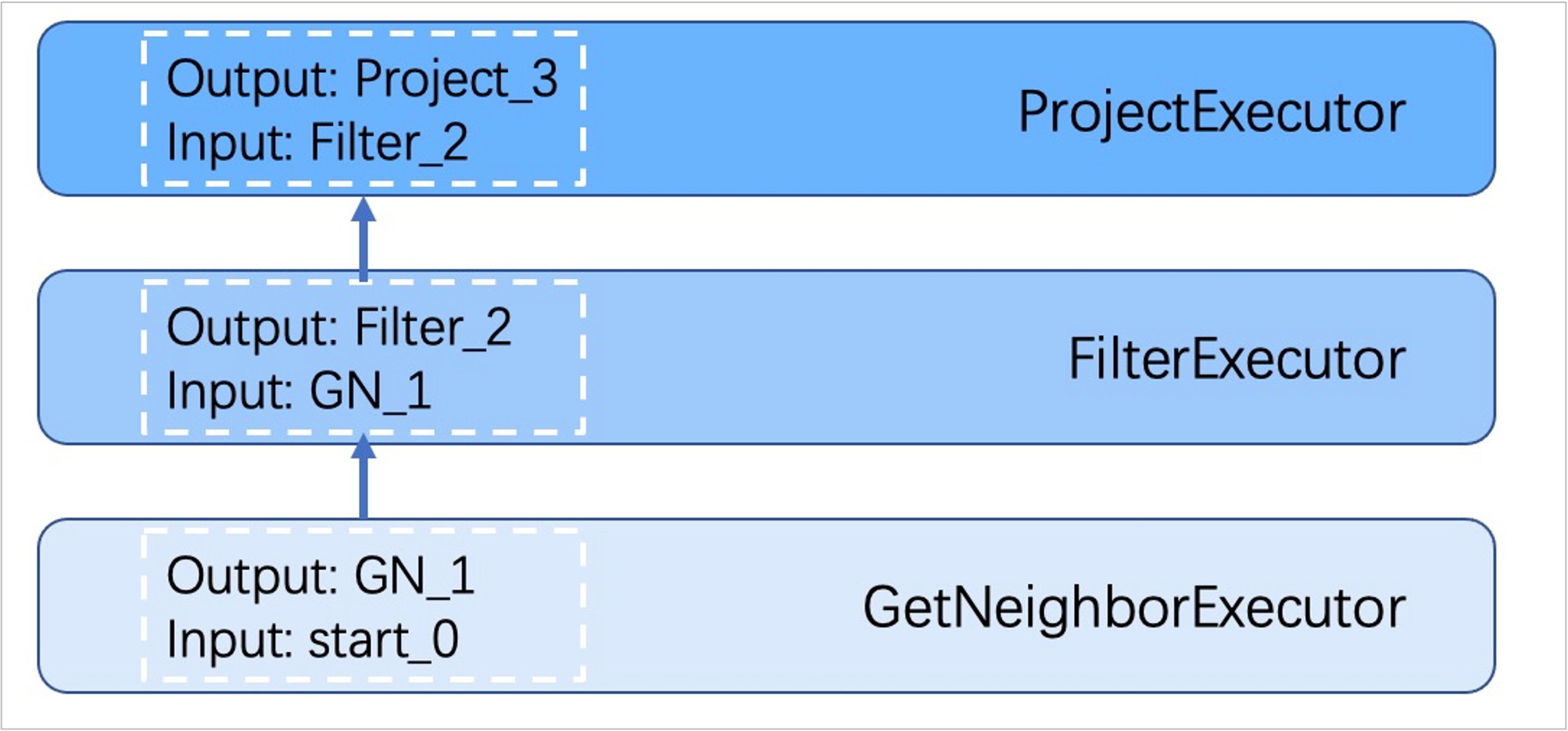
Each node of the execution plan has one execution operator node, whose input and output have been determined in the execution plan. Each operator only needs to get the values for the input variables, compute them, and finally put the results into the corresponding output variables. Therefore, it is only necessary to execute step by step from Start, and the result of the last operator is returned to the user as the final result.
Source code hierarchy¶
The source code hierarchy under the nebula-graph repository is as follows.
|--src
|--context //contexts for validation and execution
|--daemons
|--executor //execution operators
|--mock
|--optimizer //optimization rules
|--parser //lexical analysis and syntax analysis
|--planner //structure of the execution plans
|--scheduler //scheduler
|--service
|--util //basic components
|--validator //validation of the statements
|--visitor