Step 4: Use nGQL (CRUD)¶
This topic will describe the basic CRUD operations in Nebula Graph.
For more information, see nGQL guide.
Graph space and Nebula Graph schema¶
A Nebula Graph instance consists of one or more graph spaces. Graph spaces are physically isolated from each other. You can use different graph spaces in the same instance to store different datasets.
To insert data into a graph space, define a schema for the graph database. Nebula Graph schema is based on the following components.
| Schema component | Description |
|---|---|
| Vertex | Represents an entity in the real world. A vertex can have one or more tags. |
| Tag | The type of the same group of vertices. It defines a set of properties that describes the types of vertices. |
| Edge | Represents a directed relationship between two vertices. |
| Edge type | The type of an edge. It defines a group of properties that describes the types of edges. |
For more information, see Data modeling.
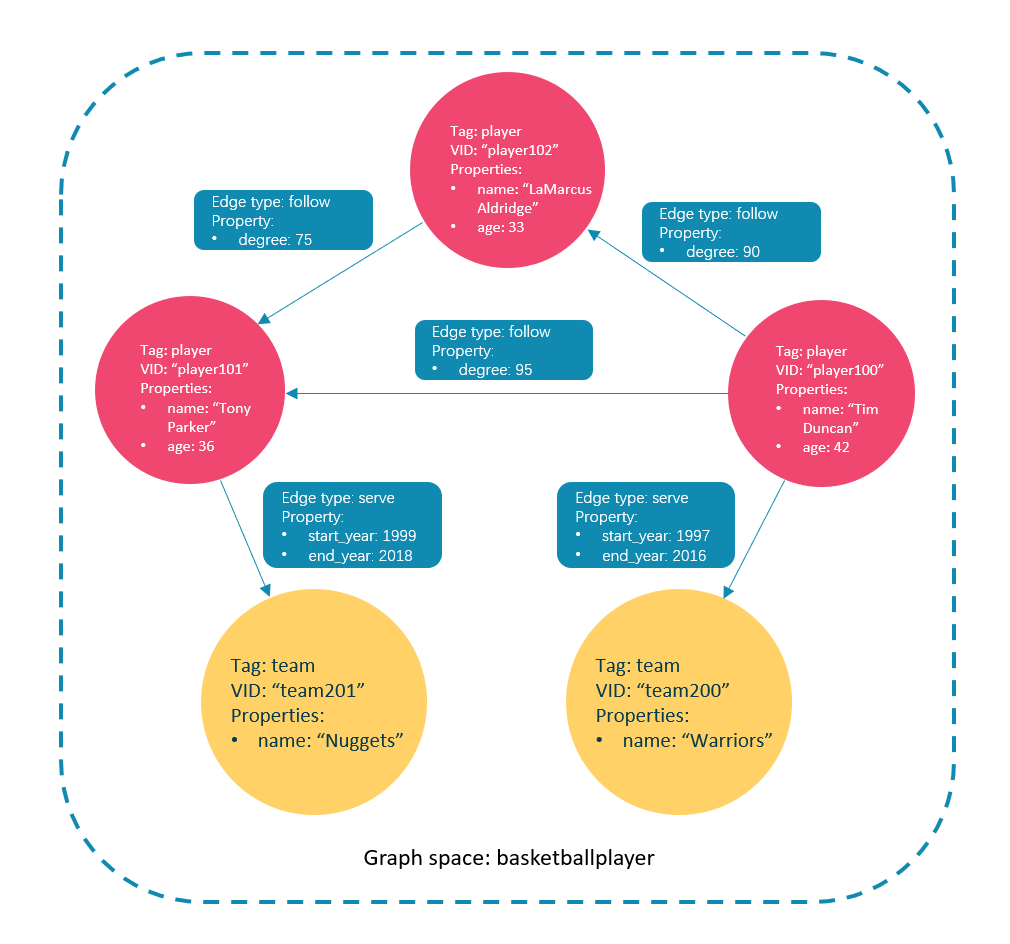
In this topic, we will use the following dataset to demonstrate basic CRUD operations.
Check the machine status in the Nebula Graph cluster¶
Note
First, we recommend that you check the machine status to make sure that all the Storage services are connected to the Meta services. Run SHOW HOSTS as follows.
nebula> SHOW HOSTS;
+-------------+-----------+-----------+--------------+----------------------+------------------------+
| Host | Port | Status | Leader count | Leader distribution | Partition distribution |
+-------------+-----------+-----------+--------------+----------------------+------------------------+
| "storaged0" | 9779 | "ONLINE" | 0 | "No valid partition" | "No valid partition" |
+-------------+-----------+-----------+--------------+----------------------+------------------------+
| "storaged1" | 9779 | "ONLINE" | 0 | "No valid partition" | "No valid partition" |
+-------------+-----------+-----------+--------------+----------------------+------------------------+
| "storaged2" | 9779 | "ONLINE" | 0 | "No valid partition" | "No valid partition" |
+-------------+-----------+-----------+--------------+----------------------+------------------------+
| "Total" | __EMPTY__ | __EMPTY__ | 0 | __EMPTY__ | __EMPTY__ |
+-------------+-----------+-----------+--------------+----------------------+------------------------+
Got 4 rows (time spent 1061/2251 us)
From the Status column of the table in the return results, you can see that all the Storage services are online.
Asynchronous implementation of creation and alteration¶
Caution
Nebula Graph implements the following creation or alteration operations asynchronously in the next heartbeat cycle. The operations will not take effect until they finish.
CREATE SPACECREATE TAGCREATE EDGEALTER TAGALTER EDGECREATE TAG INDEXCREATE EDGE INDEX
Note
The default heartbeat interval is 10 seconds. To change the heartbeat interval, modify the heartbeat_interval_secs parameter in the configuration files for all services.
To make sure the follow-up operations work as expected, take one of the following approaches:
- Run
SHOWorDESCRIBEstatements accordingly to check the status of the objects, and make sure the creation or alteration is complete. If it is not, wait a few seconds and try again.
- Wait for two heartbeat cycles, i.e., 20 seconds.
Create and use a graph space¶
nGQL syntax¶
- Create a graph space:
CREATE SPACE [IF NOT EXISTS] <graph_space_name> ( [partition_num = <partition_number>,] [replica_factor = <replica_number>,] vid_type = {FIXED_STRING(<N>) | INT64} ) [COMMENT = '<comment>'];For more information on parameters, see CREATE SPACE.
- List graph spaces and check if the creation is successful:
nebula> SHOW SPACES;
- Use a graph space:
USE <graph_space_name>;
Examples¶
-
Use the following statement to create a graph space named
basketballplayer.nebula> CREATE SPACE basketballplayer(partition_num=15, replica_factor=1, vid_type=fixed_string(30)); Execution succeeded (time spent 2817/3280 us) -
Check the partition distribution with
SHOW HOSTSto make sure that the partitions are distributed in a balanced way.nebula> SHOW HOSTS; +-------------+-----------+-----------+--------------+----------------------------------+------------------------+ | Host | Port | Status | Leader count | Leader distribution | Partition distribution | +-------------+-----------+-----------+--------------+----------------------------------+------------------------+ | "storaged0" | 9779 | "ONLINE" | 5 | "basketballplayer:5" | "basketballplayer:5" | +-------------+-----------+-----------+--------------+----------------------------------+------------------------+ | "storaged1" | 9779 | "ONLINE" | 5 | "basketballplayer:5" | "basketballplayer:5" | +-------------+-----------+-----------+--------------+----------------------------------+------------------------+ | "storaged2" | 9779 | "ONLINE" | 5 | "basketballplayer:5" | "basketballplayer:5" | +-------------+-----------+-----------+--------------+----------------------------------+------------------------+ | "Total" | | | 15 | "basketballplayer:15" | "basketballplayer:15" | +-------------+-----------+-----------+--------------+----------------------------------+------------------------+ Got 4 rows (time spent 1633/2867 us)If the Leader distribution is uneven, use
BALANCE LEADERto redistribute the partitions. For more information, see BALANCE. -
Use the
basketballplayergraph space.nebula[(none)]> USE basketballplayer; Execution succeeded (time spent 1229/2318 us)You can use
SHOW SPACESto check the graph space you created.nebula> SHOW SPACES; +--------------------+ | Name | +--------------------+ | "basketballplayer" | +--------------------+ Got 1 rows (time spent 977/2000 us)
Create tags and edge types¶
nGQL syntax¶
CREATE {TAG | EDGE} {<tag_name> | <edge_type>}(<property_name> <data_type>
[, <property_name> <data_type> ...])
[COMMENT = '<comment>'];
For more information on parameters, see CREATE TAG and CREATE EDGE.
Examples¶
Create tags player and team, edge types follow and serve. Descriptions are as follows.
| Component name | Type | Property |
|---|---|---|
| player | Tag | name (string), age (int) |
| team | Tag | name (string) |
| follow | Edge type | degree (int) |
| serve | Edge type | start_year (int), end_year (int) |
nebula> CREATE TAG player(name string, age int);
Execution succeeded (time spent 20708/22071 us)
nebula> CREATE TAG team(name string);
Execution succeeded (time spent 5643/6810 us)
nebula> CREATE EDGE follow(degree int);
Execution succeeded (time spent 12665/13934 us)
nebula> CREATE EDGE serve(start_year int, end_year int);
Execution succeeded (time spent 5858/6870 us)
Insert vertices and edges¶
Users can use the INSERT statement to insert vertices or edges based on existing tags or edge types.
nGQL syntax¶
- Insert vertices:
INSERT VERTEX [IF NOT EXISTS] <tag_name> (<property_name>[, <property_name>...]) [, <tag_name> (<property_name>[, <property_name>...]), ...] {VALUES | VALUE} <vid>: (<property_value>[, <property_value>...]) [, <vid>: (<property_value>[, <property_value>...];VIDis short for Vertex ID. AVIDmust be a unique string value in a graph space. For details, see INSERT VERTEX.
-
Insert edges:
INSERT EDGE [IF NOT EXISTS] <edge_type> (<property_name>[, <property_name>...]) {VALUES | VALUE} <src_vid> -> <dst_vid>[@<rank>] : (<property_value>[, <property_value>...]) [, <src_vid> -> <dst_vid>[@<rank>] : (<property_name>[, <property_name>...]), ...];For more information on parameters, see INSERT EDGE.
Examples¶
- Insert vertices representing basketball players and teams:
nebula> INSERT VERTEX player(name, age) VALUES "player100":("Tim Duncan", 42); Execution succeeded (time spent 28196/30896 us) nebula> INSERT VERTEX player(name, age) VALUES "player101":("Tony Parker", 36); Execution succeeded (time spent 2708/3834 us) nebula> INSERT VERTEX player(name, age) VALUES "player102":("LaMarcus Aldridge", 33); Execution succeeded (time spent 1945/3294 us) nebula> INSERT VERTEX team(name) VALUES "team200":("Warriors"), "team201":("Nuggets"); Execution succeeded (time spent 2269/3310 us)
- Insert edges representing the relations between basketball players and teams:
nebula> INSERT EDGE follow(degree) VALUES "player100" -> "player101":(95); Execution succeeded (time spent 3362/4542 us) nebula> INSERT EDGE follow(degree) VALUES "player100" -> "player102":(90); Execution succeeded (time spent 2974/4274 us) nebula> INSERT EDGE follow(degree) VALUES "player102" -> "player101":(75); Execution succeeded (time spent 1891/3096 us) nebula> INSERT EDGE serve(start_year, end_year) VALUES "player100" -> "team200":(1997, 2016), "player101" -> "team201":(1999, 2018); Execution succeeded (time spent 6064/7104 us)
Read data¶
- The GO statement can traverse the database based on specific conditions. A
GOtraversal starts from one or more vertices, along one or more edges, and returns information in a form specified in theYIELDclause.
- The FETCH statement is used to get properties from vertices or edges.
- The LOOKUP statement is based on indexes. It is used together with the
WHEREclause to search for the data that meet the specific conditions.
- The MATCH statement is the most commonly used statement for graph data querying. It can describe all kinds of graph patterns, but it relies on indexes to match data patterns in Nebula Graph. Therefore, its performance still needs optimization.
nGQL syntax¶
GOGO [[<M> TO] <N> STEPS ] FROM <vertex_list> OVER <edge_type_list> [REVERSELY] [BIDIRECT] [WHERE <expression> [AND | OR expression ...])] YIELD [DISTINCT] <return_list>;
-
FETCH-
Fetch properties on tags:
FETCH PROP ON {<tag_name> | <tag_name_list> | *} <vid_list> [YIELD [DISTINCT] <return_list>];
-
Fetch properties on edges:
FETCH PROP ON <edge_type> <src_vid> -> <dst_vid>[@<rank>] [, <src_vid> -> <dst_vid> ...] [YIELD [DISTINCT] <return_list>];
-
LOOKUPLOOKUP ON {<tag_name> | <edge_type>} WHERE <expression> [AND expression ...])] [YIELD <return_list>];
MATCHMATCH <pattern> [<WHERE clause>] RETURN <output>;
Examples of GO statement¶
- Search for the players that the player with VID
player100follows.nebula> GO FROM "player100" OVER follow; +-------------+ | follow._dst | +-------------+ | "player101" | +-------------+ | "player102" | +-------------+ Got 2 rows (time spent 12097/14220 us)
- Filter the players that the player with VID
player100follows whose age is equal to or greater than 35. Rename the corresponding columns in the results withTeammateandAge.nebula> GO FROM "player100" OVER follow WHERE $$.player.age >= 35 \ YIELD $$.player.name AS Teammate, $$.player.age AS Age; +---------------+-----+ | Teammate | Age | +---------------+-----+ | "Tony Parker" | 36 | +---------------+-----+ Got 1 rows (time spent 8206/9335 us)Clause/Sign Description YIELDSpecifies what values or results you want to return from the query. $$Represents the target vertices. \A line-breaker.
-
Search for the players that the player with VID
player100follows. Then Retrieve the teams of the players that the player with VIDplayer100follows. To combine the two queries, use a pipe or a temporary variable.-
With a pipe:
nebula> GO FROM "player100" OVER follow YIELD follow._dst AS id | \ GO FROM $-.id OVER serve YIELD $$.team.name AS Team, \ $^.player.name AS Player; +-----------+---------------+ | Team | Player | +-----------+---------------+ | "Nuggets" | "Tony Parker" | +-----------+---------------+ Got 1 rows (time spent 5055/8203 us)Clause/Sign Description $^Represents the source vertex of the edge. |A pipe symbol can combine multiple queries. $-Represents the outputs of the query before the pipe symbol.
-
With a temporary variable:
Note
Once a composite statement is submitted to the server as a whole, the life cycle of the temporary variables in the statement ends.
nebula> $var = GO FROM "player100" OVER follow YIELD follow._dst AS id; \ GO FROM $var.id OVER serve YIELD $$.team.name AS Team, \ $^.player.name AS Player; +---------+-------------+ | Team | Player | +---------+-------------+ | Nuggets | Tony Parker | +---------+-------------+ Got 1 rows (time spent 3103/3711 us)
-
Example of FETCH statement¶
Use FETCH: Fetch the properties of the player with VID player100.
nebula> FETCH PROP ON player "player100";
+----------------------------------------------------+
| vertices_ |
+----------------------------------------------------+
| ("player100" :player{age: 42, name: "Tim Duncan"}) |
+----------------------------------------------------+
Got 1 rows (time spent 2006/2406 us)
Note
The examples of LOOKUP and MATCH statements are in indexes.
Update vertices and edges¶
Users can use the UPDATE or the UPSERT statements to update existing data.
UPSERT is the combination of UPDATE and INSERT. If you update a vertex or an edge with UPSERT, the database will insert a new vertex or edge if it does not exist.
Note
UPSERT operates serially in a partition-based order. Therefore, it is slower than INSERT OR UPDATE. And UPSERT has concurrency only between multiple partitions.
nGQL syntax¶
UPDATEvertices:UPDATE VERTEX <vid> SET <properties to be updated> [WHEN <condition>] [YIELD <columns>];
UPDATEedges:UPDATE EDGE <source vid> -> <destination vid> [@rank] OF <edge_type> SET <properties to be updated> [WHEN <condition>] [YIELD <columns to be output>];
UPSERTvertices or edges:UPSERT {VERTEX <vid> | EDGE <edge_type>} SET <update_columns> [WHEN <condition>] [YIELD <columns>];
Examples¶
UPDATEthenameproperty of the vertex with VIDplayer100and check the result with theFETCHstatement.nebula> UPDATE VERTEX "player100" SET player.name = "Tim"; Execution succeeded (time spent 3483/3914 us) nebula> FETCH PROP ON player "player100"; +---------------------------------------------+ | vertices_ | +---------------------------------------------+ | ("player100" :player{age: 42, name: "Tim"}) | +---------------------------------------------+ Got 1 rows (time spent 2463/3042 us)
UPDATEthedegreeproperty of an edge and check the result with theFETCHstatement.nebula> UPDATE EDGE "player100" -> "player101" OF follow SET degree = 96; Execution succeeded (time spent 3932/4432 us) nebula> FETCH PROP ON follow "player100" -> "player101"; +----------------------------------------------------+ | edges_ | +----------------------------------------------------+ | [:follow "player100"->"player101" @0 {degree: 96}] | +----------------------------------------------------+ Got 1 rows (time spent 2205/2800 us)
- Insert a vertex with VID
player111andUPSERTit.nebula> INSERT VERTEX player(name, age) VALUES "player111":("Ben Simmons", 22); Execution succeeded (time spent 2115/2900 us) Wed, 21 Oct 2020 11:11:50 UTC nebula> UPSERT VERTEX "player111" SET player.name = "Dwight Howard", player.age = $^.player.age + 11 \ WHEN $^.player.name == "Ben Simmons" AND $^.player.age > 20 \ YIELD $^.player.name AS Name, $^.player.age AS Age; +---------------+-----+ | Name | Age | +---------------+-----+ | Dwight Howard | 33 | +---------------+-----+ Got 1 rows (time spent 1815/2329 us)
Delete vertices and edges¶
nGQL syntax¶
- Delete vertices:
DELETE VERTEX <vid1>[, <vid2>...]
- Delete edges:
DELETE EDGE <edge_type> <src_vid> -> <dst_vid>[@<rank>] [, <src_vid> -> <dst_vid>...]
Examples¶
- Delete vertices:
nebula> DELETE VERTEX "team1", "team2"; Execution succeeded (time spent 4337/4782 us)
- Delete edges:
nebula> DELETE EDGE follow "team1" -> "team2"; Execution succeeded (time spent 3700/4101 us)
About indexes¶
Users can add indexes to tags and edge types with the CREATE INDEX statement.
Must-read for using indexes
Both MATCH and LOOKUP statements depend on the indexes. But indexes can dramatically reduce the write performance (as much as 90% or even more). DO NOT use indexes in production environments unless you are fully aware of their influences on your service.
Users MUST rebuild indexes for pre-existing data. Otherwise, the pre-existing data cannot be indexed and therefore cannot be returned in MATCH or LOOKUP statements. For more information, see REBUILD INDEX.
nGQL syntax¶
- Create an index:
CREATE {TAG | EDGE} INDEX [IF NOT EXISTS] <index_name> ON {<tag_name> | <edge_name>} ([<prop_name_list>]) [COMMENT = '<comment>'];
- Rebuild an index:
REBUILD {TAG | EDGE} INDEX <index_name>;
Examples¶
Create and rebuild indexes for the name property on all vertices with the tag player.
nebula> CREATE TAG INDEX player_index_0 on player(name(20));
nebula> REBUILD TAG INDEX player_index_0;
Note
Define the index length when creating an index for a variable-length property. In UTF-8 encoding, a non-ascii character occupies 3 bytes. You should set an appropriate index length according to the variable-length property. For example, the index should be 30 bytes for 10 non-ascii characters. For more information, see CREATE INDEX
Examples of LOOKUP and MATCH (index-based)¶
Make sure there is an index for LOOKUP or MATCH to use. If there is not, create an index first.
Find the information of the vertex with the tag player and its value of the name property is Tony Parker.
This example creates the index player_name_0 on the player name property.
nebula> CREATE TAG INDEX player_name_0 on player(name(10));
Execution succeeded (time spent 3465/4150 us)
This example rebuilds the index to make sure it takes effect on pre-existing data.
nebula> REBUILD TAG INDEX player_name_0
+------------+
| New Job Id |
+------------+
| 31 |
+------------+
Got 1 rows (time spent 2379/3033 us)
This example uses the LOOKUP statement to retrieve the vertex property.
nebula> LOOKUP ON player WHERE player.name == "Tony Parker" \
YIELD player.name, player.age;
+-------------+---------------+------------+
| VertexID | player.name | player.age |
+-------------+---------------+------------+
| "player101" | "Tony Parker" | 36 |
+-------------+---------------+------------+
This example uses the MATCH statement to retrieve the vertex property.
nebula> MATCH (v:player{name:"Tony Parker"}) RETURN v;
+-----------------------------------------------------+
| v |
+-----------------------------------------------------+
| ("player101" :player{age: 36, name: "Tony Parker"}) |
+-----------------------------------------------------+
Got 1 rows (time spent 5132/6246 us)